Summary:
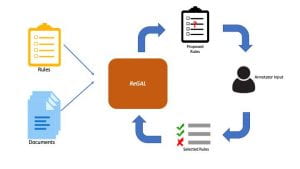
Obtaining sufficient labeled data to train generalizable models is a major bottleneck for machine learning, especially in health care and life sciences where significant subject matter expertise is required to provide accurate labels. Accordingly, we design algorithms that can effectively learn from limited data using weak supervision and semi-supervised/self-supervised learning. These models use active learning to interactively solicit the information they need to improve from human annotators, which may come in the form of targeted datapoints for labeling or additional labeling functions. Our approach makes it fast and simple to develop machine learning models for new tasks and enables us to more effectively leverage the subject matter experts (e.g. clinicians) under limited time budgets.
Team Leader:
David Kartchner, Davi Nakajima
Poster:

Figures: