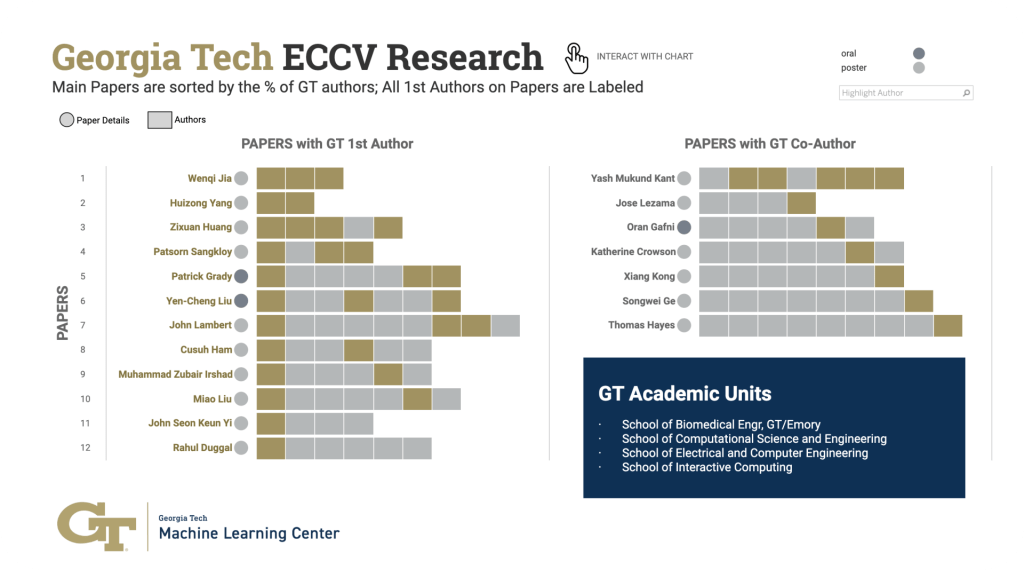
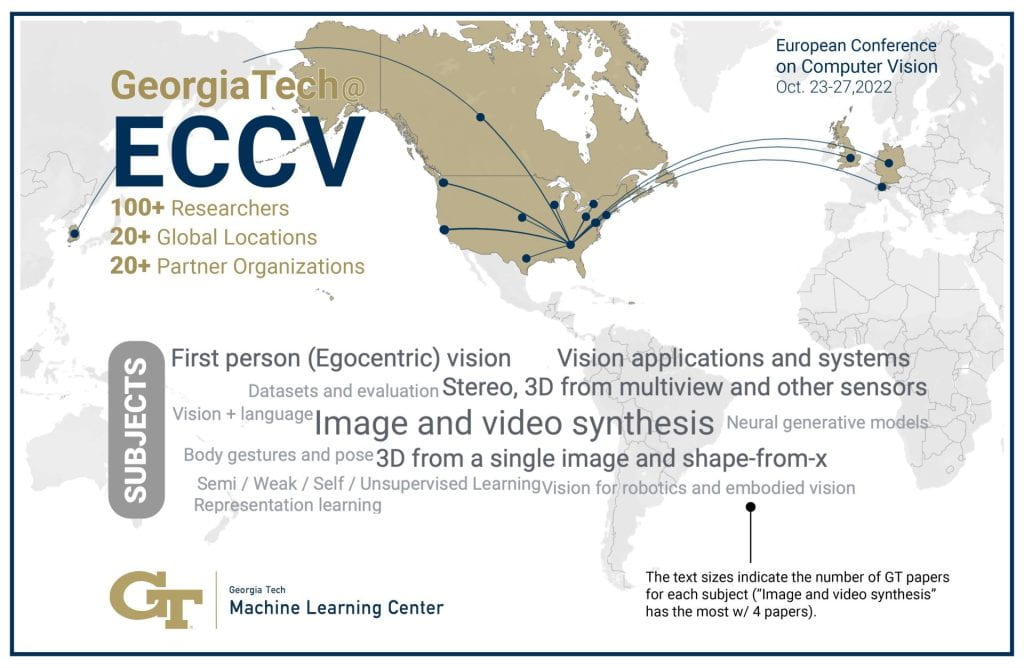
Georgia Tech at ECCV 2022
Computer vision research involves creating the next generation of machines to understand videos and images as easily as humans can. Georgia Tech’s latest contributions to the field will be presented Oct. 23-27 at the European Conference on Computer Vision.
Explore Georgia Tech’s latest work, the experts behind the tech, and where computer vision is headed next.