
Summary
Discover the fascinating journey of clustering algorithms from their inception in the early 20th century to the cutting-edge advancements of the 2020s. This article unveils the evolution of these algorithms, beginning with their foundational use in anthropology and psychology, through to the development of key methodologies such as the K-Means algorithm in the 1950s, Hierarchical Clustering in the 1960s, and the innovative DBSCAN algorithm in the 1990s. The narrative continues into the 2000s with the introduction of algorithms designed to efficiently manage larger datasets and complex data types, culminating in the latest domain-specific deep learning approaches. Explore the milestones that have shaped the trajectory of clustering algorithms, highlighting the continuous pursuit of refining and enhancing their capabilities for a myriad of applications.
History of Clustering
The history of clustering algorithms dates back to the early 20th century, foundationally originating in the realms of anthropology and psychology in the 1930s [1, 2] . It was introduced in anthropology by Driver and Kroeber in 1932 [3] to simplify the ambiguity of empirically based typologies of cultures and individuals. In the field of psychology, it was famously used by Cattell beginning in 1943 [4] for trait theory classification in personality psychology, to organise and analyse the meaningful information from psychological data. Through the 1960s, clustering became more popular in diverse fields such as social science, medicine, biology and geography [4].
Milestones
At the core, clustering is a method of unsupervised learning that helps in the grouping of objects based on how similar they are to each other. Over time, the development of these algorithms has been marked by the introduction of new methods for identifying similarity, followed by improvements along time and adaptations to handle larger datasets and complex data types.
- 1950s : K-Means
- 1957 The concept of Clustering was first introduced with the K-Means algorithm by Stuart Lloyd at Bell Labs, although it wasn’t published until 1982 [5]. Although it was first intended for pulse-code modulation, the wide-spread adoption was in the field of data clustering.
- 1960s: Hierarchical Clustering
- 1963 The hierarchical clustering method was formulated, that focuses on building a hierarchy of clusters, that can be visualised using a dendrogram—a tree-like diagram that records the sequences of merges or splits. [6]
- 1990s: DBSCAN
- 1996 The DBSCAN (Density-Based Spatial Clustering of Applications with Noise) algorithm was formally published and named in 1996 [7], introducing a method that could find arbitrarily shaped clusters and deal with noise in the data. Towards the later part of the decade, further advancements in this algorithm were made to extend the capability to handle data of varying density.
- 2000s: BIRCH, CURE
- 2000 The concept of pre-clustering was introduced with the Canopy Clustering [8] algorithm, since the traditional clustering algorithms were expensive when the dataset is large. In this method, the approximate distance measures were initially used to efficiently divide large data into overlapping subsets, and only then employ the expensive distance measurements.
- 2002 The BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies) algorithm [9] was introduced to handle very large datasets. This algorithm dynamically and incrementally clusters incoming multi-dimensional metric data points to produce high-quality clustering results with minimal resource usage.
- 2003 The CURE (Clustering Using Representatives) algorithm [10] was developed to more effectively cluster data with a wide range of shapes and sizes. CURE combines representative point selection, hierarchical clustering, and outlier handling for efficient clustering on complex structures.
- 2010s: HDBSCAN
- 2014 The HDBSCAN (Hierarchical DBSCAN) algorithm was introduced, which was an extension of DBSCAN that applies a hierarchy-based approach to density based clustering in order to improve flexibility and cluster detection.
- 2020s : AI and Beyond
- Development of domain-specific clustering deep learning algorithms that cater to specific challenges in fields like bioinformatics, social network analysis etc [11] as well as techniques like auto encoder-based and deep embedded clustering [12].
Taxonomy
At the onset, there are two broad categories of clustering, partition based and hierarchical. While partitional clustering requires defining the number of clusters beforehand and grouping the objects based on similarity, hierarchical clustering involves constructing a hierarchy among sensitive attribute values to split them into clusters. [13]
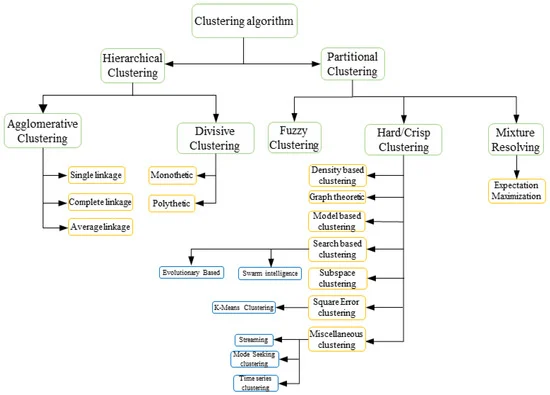
Source : A Taxonomy of Machine Learning Clustering Algorithms [13]
Within the hierarchical mode, one can either consider all of the samples as one cluster and then split them recursively (divisive) or merge the nearest clusters iteratively (agglomerative). Partitional algorithms on the other hand, partition a dataset into the specified number of distinct clusters where each point belongs to exactly one cluster. Within this class of algorithms, the partitioning is done based on organizational approaches to clustering, i.e. density based, centroid based and distribution. We will now discuss the advanced versions of both the centroid based and density based algorithms discussed in class below.
Centroid based (K-Medoids)
While K-Means is efficient and widely used for its simplicity and speed, K-Medoids or Partitioning Around Medoid (PAM) [14] offers advantages in terms of robustness to outliers and flexibility in handling various data types and distance measures. In this algorithm, actual data points are chosen as medoids instead of the mean of the data points. Once these K representative objects are chosen, each of the samples are assigned to the nearest medoid based on the suitable distance metric. In the next step, for each cluster formed, the point that minimises the total distance to all other points in the cluster is identified and selected as the new medoid. Finally, check for the convergence condition, when the medoids identified no longer get updated. In case some of the medoids change, repeat the above steps till the final convergence is achieved.
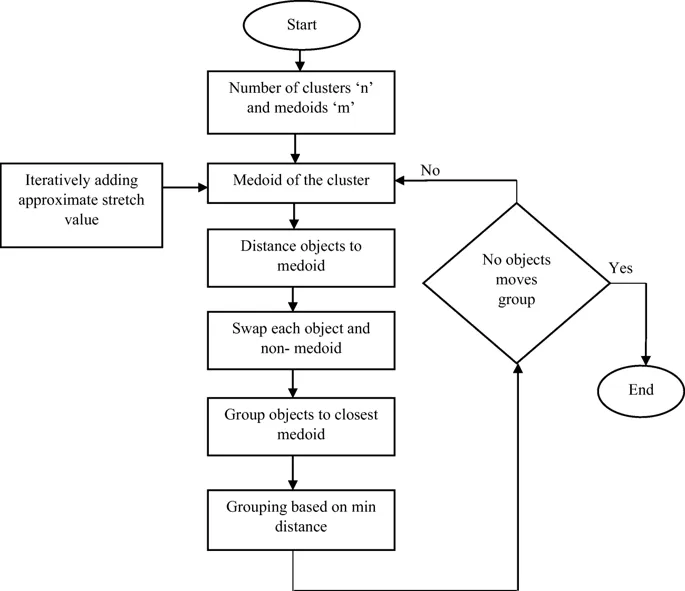
Source : Partitional Clustering
Due to the nature of this algorithm, K-Medoids is particularly useful in applications where the clusters are expected to be non-spherical or when the dataset contains outliers since the clustering is independent of mean average of the samples. In addition, the K-Medoids approach offers more flexibility in terms of data types as a variety of distance measures can be employed. It is also particularly preferred when a representative example (actual data point) is required for each cluster.
Density based (DBSCAN)
The DBSCAN (Density-Based Spatial Clustering of Applications with Noise) algorithm was proposed by Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu in 1996 [7]. It is popular for its ability to handle noise in the dataset as well as identify clusters of different shapes and sizes. DBSCAN achieves this by primarily classifying the available points as either core points, border points, or noise points based on the number of points within a certain ‘ε’ epsilon radius.
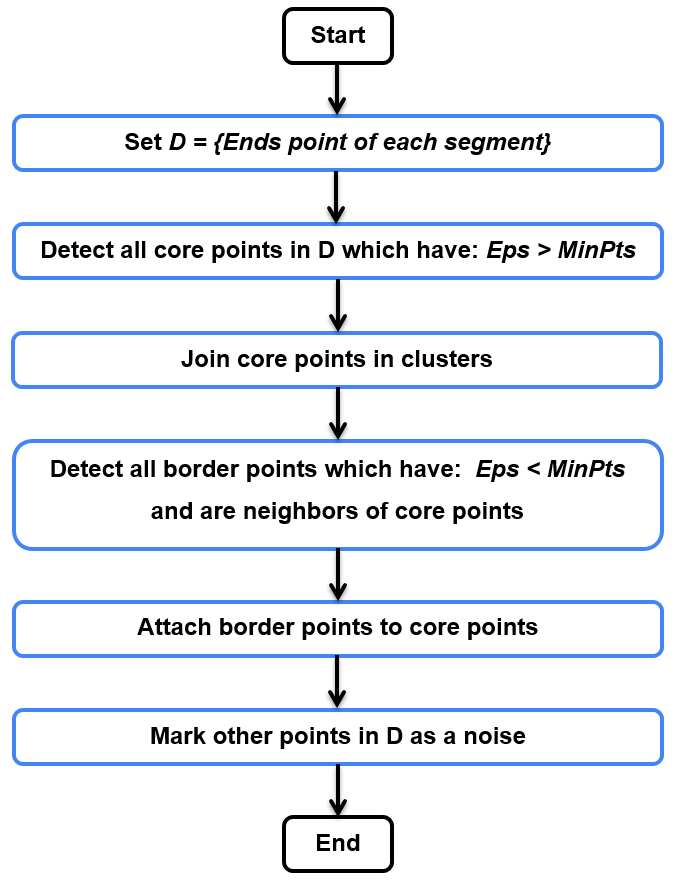
Source : DBSCAN Clustering Algorithm [15]
In the first part of the DBSCAN algorithm initialization, start with an unvisited point and check for the number of points in the epsilon neighborhood. If this number exceeds the threshold ‘MinPts” set, mark it as either a core point and form a cluster, or update the existing cluster or mark it as noise. Recursively, consider all the points in the neighborhood and add them to the cluster. Iterate this process over all the unvisited points and the algorithm terminates when all the points have been marked.
The key advantage that DBSCAN offers is its robustness to noise as it separates out the low-density clusters and offers flexibility required through controlling the thresholds of epsilon and MinPts. In addition, unlike k-means, DBSCAN does not assume that clusters are spherical and is able to accommodate various shapes and sizes.
Summary
In summary, each clustering method has its own strengths and weaknesses. Centroid-based clustering is simple and scalable but requires prior knowledge of the number of clusters. Distribution-based clustering accounts for variance and provides probabilities but can be computationally expensive. Density-based clustering doesn’t require predefined clusters and handles irregular shapes well but may struggle with varying densities. Hierarchical clustering doesn’t require a preset number of clusters and offers visual insights but can be computationally intensive and subjective in interpretation. The choice of clustering method depends on the characteristics of the dataset and the specific requirements of the analysis. The table below provides a guideline for choosing these techniques based on the different dataset attributes and clustering requirements.
| Algorithm | Unknown Number of Clusters | Measure of Uncertainty (confidence) | Robust to Noise | Robust to Initialisations | Scale to large Datasets | Interpretability | Implementation |
| K Means | No | No | No | No | Yes | No | Scikit-Learn |
| K Medoids | No | No | Yes | Yes | No | Yes | Scikit-Learn-Extra |
| GMM | No | Yes | No | Yes | No | No | Scikit-Learn |
| DB SCAN | Yes | No | Yes | No | No | No | Scikit-Learn |
| Hierarchical | Yes | No | No | Yes | No | Yes | Scikit-Learn |
Featured cover image generated by DALLE 3.
References
- Driver, H. E. and A. L. Kroeber (1932) Quantitative expression of cultural relationships. University of California Publications in American Archaeology and Ethnology 31: 211-56.
- Tryon, Robert C. (1939). Cluster Analysis: Correlation Profile and Orthometric (factor) Analysis for the Isolation of Unities in Mind and Personality. Edwards Brothers.
- Driver and Kroeber (1932). “Quantitative Expression of Cultural Relationships”. University of California Publications in American Archaeology and Ethnology. Berkeley, CA: University of California Press. Quantitative Expression of Cultural Relationships: 211–256
- Cattell, R. B. (1943). “The description of personality: Basic traits resolved into clusters”. Journal of Abnormal and Social Psychology 38: 476–506. doi: 10.1037/h0054116
- Pérez-Ortega, J., Nely Almanza-Ortega, N., Vega-Villalobos, A., Pazos-Rangel, R., Zavala-Díaz, C., & Martínez-Rebollar, A. (2020). The K-Means Algorithm Evolution. IntechOpen. doi: 10.5772/intechopen.85447
- Murtagh, F., Legendre, P. Ward’s Hierarchical Agglomerative Clustering Method: Which Algorithms Implement Ward’s Criterion?. J Classif 31, 274–295 (2014). https://doi.org/10.1007/s00357-014-9161-z
- Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. 1996. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD’96). AAAI Press, 226–231.
- McCallum, A.; Nigam, K.; and Ungar L.H. (2000) “Efficient Clustering of High Dimensional Data Sets with Application to Reference Matching”, Proceedings of the sixth ACM SIGKDD international conference on Knowledge discovery and data mining, 169-178 doi:10.1145/347090.347123
- Zhang, T., Ramakrishnan, R. & Livny, M. BIRCH: A New Data Clustering Algorithm and Its Applications. Data Mining and Knowledge Discovery 1, 141–182 (1997). https://doi.org/10.1023/A:1009783824328
- Sudipto Guha, Rajeev Rastogi, Kyuseok Shim,Cure: an efficient clustering algorithm for large databases,Information Systems,Volume 26, Issue 1,2001, Pages 35-58, ISSN 0306-4379, https://doi.org/10.1016/S0306-4379(01)00008-4.
- Md Rezaul Karim, Oya Beyan, Achille Zappa, Ivan G Costa, Dietrich Rebholz-Schuhmann, Michael Cochez, Stefan Decker, Deep learning-based clustering approaches for bioinformatics, Briefings in Bioinformatics, Volume 22, Issue 1, January 2021, Pages 393–415, https://doi.org/10.1093/bib/bbz170
- Bassoma Diallo, Jie Hu, Tianrui Li, Ghufran Ahmad Khan, Xinyan Liang, Yimiao Zhao, Deep embedding clustering based on contractive autoencoder, Neurocomputing, Volume 433, 2021,Pages 96-107, ISSN 0925-2312, https://doi.org/10.1016/j.neucom.2020.12.094.
- Pitafi S, Anwar T, Sharif Z. A Taxonomy of Machine Learning Clustering Algorithms, Challenges, and Future Realms. Applied Sciences. 2023; 13(6):3529. https://doi.org/10.3390/app13063529
- Preeti Arora, Deepali, Shipra Varshney, Analysis of K-Means and K-Medoids Algorithm For Big Data, Procedia Computer Science, Volume 78, 2016, Pages 507-512, ISSN 1877-0509, https://doi.org/10.1016/j.procs.2016.02.095.
- El Bahi, Hassa, Zatni, Abdelkarim, 2018/02/05, Document text detection in video frames acquired by a smartphone based on line segment detector and DBSCAN clustering, Journal of Engineering Science and Technology