International Conference on Computer Vision (ICCV 2023)
Oct. 2 – 6 | Paris
Georgia Tech’s research at ICCV covers a wide range of topics in computer vision and artificial intelligence and showcases our experts’ innovations in solving complex problems.
From improving neural architectures to using synthetic data for large-language models to generating human motion from text prompts – for applications in robotics and animation – Georgia Tech is advancing the state-of-the-art in computer vision. Explore now.
________Georgia Tech at ICCV 2023
Georgia Tech is a leading contributor to ICCV 2023, a research venue focused on computer vision, a subfield of artificial intelligence that, at its simplest, is about training computers to process image and video pixels so they “see” the world as people do. .
Partner Organizations
Ant Financial • BioMap (Beijing) Intelligence Technology Limited • Caltech • Carnegie Mellon University • CASIA • Chinese Academy of Sciences • Ecole des Ponts ParisTech • Google • Massachusetts Institute of Technology • Meta • MIT-IBM Watson AI Lab • Northeastern University • Oregon State University • Rice University • Toyota Research Institute • University at Buffalo • University of California at Berkeley • University of Illinois Urbana-Champaign
Georgia Tech Authors
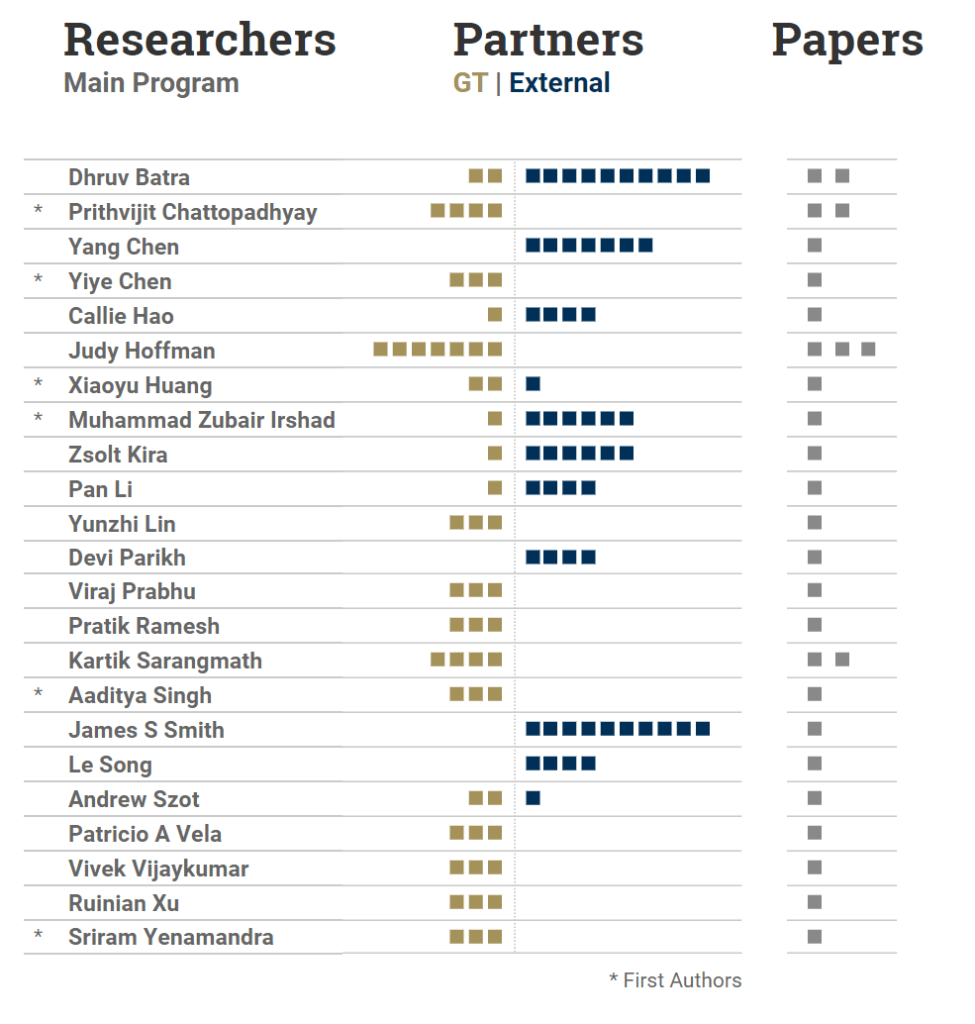
Researchers work in teams of all sizes and on multiple teams with different specialties. Listed alphabetically are Georgia Tech’s 23 authors in the main papers program with their number of team members.
Faculty

Dhruv Batra
Assoc. Professor, Interactive Computing

Callie Hao
Asst. Professor, Electrical and Computer Engineering

Judy Hoffman
Asst. Professor, Interactive Computing

Zsolt Kira
Asst. Professor, Interactive Computing

Pan Li
Asst. Professor, Electrical and Computer Engineering

Devi Parikh
Assoc. Professor, Interactive Computing

Patricio A. Vela
Professor, Electrical and Computer Engineering
RESEARCH
Benchmarking Low-Shot Robustness to Natural Distribution Shifts
Aaditya Singh (Georgia Institute of Technology); Kartik Sarangmath (Georgia Institute of Technology); Prithvijit Chattopadhyay (Georgia Institute of Technology)*; Judy Hoffman (Georgia Tech)
Robustness to natural distribution shifts has seen remarkable progress thanks to recent pre-training strategies combined with better fine-tuning methods. However, such fine-tuning assumes access to large amounts of labelled data, and the extent to which the observations hold when the amount of training data is not as high remains unknown. We address this gap by performing the first in-depth study of robustness to various natural distribution shifts in different low-shot regimes: spanning datasets, architectures, pre-trained initializations, and state-of-the-art robustness interventions. Most importantly, we find that there is no single model of choice that is often more robust than others, and existing interventions can fail to improve robustness on some datasets even if they do so in the full-shot regime. We hope that our work will motivate the community to focus on this problem of practical importance.
Extensible and Efficient Proxy for Neural Architecture Search
Yuhong Li (University of Illinois at Urbana and Champaign)*; Jiajie Li (University at Buffalo); Callie Hao (Georgia Institute of Technology); Pan Li (Georgia Tech.); Jinjun Xiong (University at Buffalo); Deming Chen (University of Illinois at Urbana-Champaign)
Efficient or near-zero-cost proxies were proposed recently to address the demanding computational issues of Neural Architecture Search (NAS) in designing deep neural networks (DNNs), where each candidate architecture network only requires one iteration of backpropagation. The values obtained from proxies are used as predictions of architecture performance for downstream tasks. However, two significant drawbacks hinder the wide adoption of these efficient proxies: 1. they are not adaptive to various NAS search spaces and 2. they are not extensible to multi-modality downstream tasks. To address these two issues, we first propose an Extensible proxy (Eproxy) that utilizes self-supervised, few-shot training to achieve near-zero costs. A key component to our Eproxy’s efficiency is the introduction of a barrier layer with randomly initialized frozen convolution parameters, which adds non-linearities to the optimization spaces so that Eproxy can discriminate the performance of architectures at an early stage. We further propose a Discrete Proxy Search (DPS) method to find the optimized training settings for Eproxy with only a handful of benchmarked architectures on the target tasks. Our extensive experiments confirm the effectiveness of both Eproxy and DPS. On the NDS-ImageNet search spaces, Eproxy+DPS achieves a higher average ranking correlation (Spearman ρ = 0.73) than the previous efficient proxy (Spearman ρ = 0.56). On the NAS-Bench-Trans-Micro search spaces with seven tasks, Eproxy+DPS delivers comparable performance with the early stopping method (146× faster). For the end-to-end task such as DARTS-ImageNet-1k, our method delivers better results than NAS performed on CIFAR-10 while only requiring one GPU hour with a single batch of CIFAR-10 images.
FACTS: First Amplify Correlations and Then Slice to Discover Bias
Sriram Yenamandra (Georgia Institute of Technology)*; Pratik Ramesh (Georgia Institute of Technilogy); Viraj Prabhu (Georgia Tech); Judy Hoffman (Georgia Tech)
Computer vision datasets frequently contain spurious correlations between task-relevant labels and (easy to learn) latent task-irrelevant attributes (e.g. context). Models trained on such datasets learn “shortcuts” and underperform on bias-conflicting slices of data where the correlation does not hold. In this work, we study the problem of identifying such slices to inform downstream bias mitigation strategies. We propose First Amplify Correlations and Then Slice (FACTS), wherein we first amplify correlations to fit a simple bias-aligned hypothesis via strongly regularized empirical risk minimization. Next, we perform correlation-aware slicing via mixture modeling in bias-aligned feature space to discover underperforming data slices that capture distinct correlations. Despite its simplicity, our method considerably improves over prior work (by as much as 35% precision@10) in correlation bias identification across a range of diverse evaluation settings. Our code is available at https://github.com/yvsriram/FACTS.
Going Beyond Nouns With Vision & Language Models Using Synthetic Data
Paola Cascante-Bonilla (Rice University)*; Khaled Shehada (Massachusetts Institute of Technology); James S Smith (Georgia Institute of Technology); Sivan Doveh (IBM-Research); Donghyun Kim (MIT-IBM Watson AI Lab); Rameswar Panda (MIT-IBM Watson AI Lab); Gul Varol (Ecole des Ponts ParisTech); Aude Oliva (MIT); Vicente Ordonez (Rice University); Rogerio Feris (MIT-IBM Watson AI Lab, IBM Research); Leonid Karlinsky (IBM-Research)
Large-scale pre-trained Vision & Language (VL) models have shown remarkable performance in many applications, enabling replacing a fixed set of supported classes with zero-shot open vocabulary reasoning over (almost arbitrary) natural language prompts. However, recent works have uncovered a fundamental weakness of these models. For example, their difficulty to understand Visual Language Concepts (VLC) that go ‘beyond nouns’ such as the meaning of non-object words (e.g., attributes, actions, relations, states, etc.), or difficulty in performing compositional reasoning such as understanding the significance of the order of the words in a sentence. In this work, we investigate to which extent purely synthetic data could be leveraged to teach these models to overcome such shortcomings without compromising their zero-shot capabilities. We contribute Synthetic Visual Concepts (SyViC) – a million-scale synthetic dataset and data generation codebase allowing to generate additional suitable data to improve VLC understanding and compositional reasoning of VL models. Additionally, we propose a general VL finetuning strategy for effectively leveraging SyViC towards achieving these improvements. Our extensive experiments and ablations on VL-Checklist, Winoground, and ARO benchmarks demonstrate that it is possible to adapt strong pre-trained VL models with synthetic data significantly enhancing their VLC understanding (e.g. by 9.9% on ARO and 4.3% on VL-Checklist) with under 1% drop in their zero-shot accuracy.
Make-An-Animation: Large-Scale Text-conditional 3D Human Motion Generation
Samaneh Azadi (Meta AI)*; Mian Akbar Shah (Meta Platforms Inc); Thomas F Hayes (Meta); Devi Parikh (Georgia Tech & Facebook AI Research); Sonal Gupta (Facebook)
Text-guided human motion generation has drawn significant interest because of its impactful applications spanning animation and robotics. Recently, application of diffusion models for motion generation has enabled improvements in the quality of generated motions. However, existing approaches are limited by their reliance on relatively small-scale motion capture data, leading to poor performance on more diverse, in-the-wild prompts. In this paper, we introduce Make-An-Animation, a text-conditioned human motion generation model which learns more diverse poses and prompts from large-scale image-text datasets, enabling significant improvement in performance over prior works. Make-An-Animation is trained in two stages. First, we train on a curated large-scale dataset of (text, static pseudo-pose) pairs extracted from image-text datasets. Second, we fine-tune on motion capture data, adding additional layers to model the temporal dimension. Unlike prior diffusion models for motion generation, Make-An-Animation uses a U-Net architecture similar to recent text-to-video generation models. Human evaluation of motion realism and alignment with input text shows that our model reaches state-of-the-art performance on text-to-motion generation.
Navigating to Objects Specified by Images
Jacob Krantz (Oregon State University)*; Theophile Gervet (Carnegie Mellon University); Karmesh Yadav (Facebook AI Research); Austin S Wang (Facebook AI Research); Chris Paxton (Meta AI); Roozbeh Mottaghi (FAIR @ Meta ); Dhruv Batra (Georgia Tech & Facebook AI Research); Jitendra Malik (University of California at Berkeley); Stefan Lee (Oregon State University); Devendra Singh Chaplot (Facebook AI Research)
Images are a convenient way to specify which particular object instance an embodied agent should navigate to. Solving this task requires semantic visual reasoning and exploration of unknown environments. We present a system that can perform this task in both simulation and the real world. Our modular method solves sub-tasks of exploration, goal instance re-identification, goal localization, and local navigation. We re-identify the goal instance in egocentric vision using feature-matching and localize the goal instance by projecting matched features to a map. Each sub-task is solved using off-the-shelf components requiring zero fine-tuning. On the HM3D InstanceImageNav benchmark, this system outperforms a baseline end-to-end RL policy 7x and outperforms a state-of-the-art ImageNav model 2.3x (56% vs. 25% success). We deploy this system to a mobile robot platform and demonstrate effective performance in the real world, achieving an 88% success rate across a home and an office environment.
NeO 360: Neural Fields for Sparse View Synthesis of Outdoor Scenes
Muhammad Zubair Irshad (Georgia Institute of Technology)*; Sergey Zakharov (Toyota Research Institute); Katherine Liu (Toyota Research Institute); Vitor Guizilini (Toyota Research Institute); Thomas Kollar (Toyota Research Institute); Adrien Gaidon (Toyota Research Institute); Zsolt Kira (Georgia Institute of Technology); Rareș A Ambruș (Toyota Research Institute)
Recent implicit neural representations have shown great results for novel view synthesis. However, existing methods require expensive per-scene optimization from many views hence limiting their application to real-world unbounded urban settings where the objects of interest or backgrounds are observed from very few views. To mitigate this challenge, we introduce a new approach called NeO 360, Neural fields for sparse view synthesis of outdoor scenes. NeO 360 is a generalizable method that reconstructs 360° scenes from a single or a few posed RGB images. The essence of our approach is in capturing the distribution of complex real-world outdoor 3D scenes and using a hybrid image-conditional triplanar representation that can be queried from any world point. Our representation combines the best of both voxel-based and bird’s-eye-view (BEV) representations and is more effective and expressive than each. NeO 360’s representation allows us to learn from a large collection of unbounded 3D scenes while offering generalizability to new views and novel scenes from as few as a single image during inference. We demonstrate our approach on the proposed challenging 360° unbounded dataset, called NeRDS 360, and show that NeO 360 outperforms state-of-the-art generalizable methods for novel view synthesis while also offering editing and composition capabilities. Project page: zubair-irshad.github.io/projects/neo360.html
Open-domain Visual Entity Recognition: Towards Recognizing Millions of Wikipedia Entities
Hexiang Hu (Google)*; Yi Luan (Google Brain); Yang Chen (Georgia Institute of Technology); Urvashi Khandelwal (Google); Mandar Joshi (Google); Kenton Lee (Google); Mingwei Chang (Google); Kristina N Toutanova (Google)
Large-scale multi-modal pre-training models such as CLIP and PaLI exhibit strong generalization on various visual domains and tasks. However, existing image classification benchmarks often evaluate recognition on a specific domain (e.g., outdoor images) or a specific task (e.g., classifying plant species), which falls short of evaluating whether pre-trained foundational models are universal visual recognizers. To address this, we formally present the task of Open-domain Visual Entity recognitioN (OVEN), where a model need to link an image onto a Wikipedia entity with respect to a text query. We construct OVEN by re-purposing 14 existing datasets with all labels grounded onto one single label space: Wikipedia entities. OVEN challenges models to select among six million possible Wikipedia entities, making it a general visual recognition benchmark with largest number of labels. Our study on state-of-the-art pre-trained models reveals large headroom in generalizing to the massive-scale label space. We show that a PaLI-based auto-regressive visual recognition model performs surprisingly well, even on Wikipedia entities that have never been seen during fine-tuning. We also find existing pre-trained models yield different unique strengths: while PaLI-based models obtains higher overall performance, CLIP-based models are better at recognizing tail entities.
PASTA: Proportional Amplitude Spectrum Training Augmentation for Syn-to-Real Domain Generalization
Prithvijit Chattopadhyay (Georgia Institute of Technology)*; Kartik Sarangmath (Georgia Institute of Technology); Vivek Vijaykumar (Georgia Tech); Judy Hoffman (Georgia Tech)
Synthetic data offers the promise of cheap and bountiful training data for settings where labeled real-world data is scarce. However, models trained on synthetic data significantly underperform when evaluated on real-world data. In this paper, we propose Proportional Amplitude Spectrum Training Augmentation (PASTA), a simple and effective augmentation strategy to improve out-of-the-box synthetic-to-real (syn-to-real) generalization performance. PASTA perturbs the amplitude spectra of synthetic images in the Fourier domain to generate augmented views. Specifically, with PASTA we propose a structured perturbation strategy where high-frequency components are perturbed relatively more than the low-frequency ones. For the tasks of semantic segmentation (GTAV→Real), object detection (Sim10K→Real), and object recognition (VisDA-C Syn→Real), across a total of 5 syn-to-real shifts, we find that PASTA outperforms more complex state-of-the-art generalization methods while being complementary to the same.
Pixel-Aligned Recurrent Queries for Multi-View 3D Object Detection
Yiming Xie (Northeastern University); Huaizu Jiang (Northeastern University); Georgia Gkioxari (Caltech)*; Julian Straub (MIT)
We present PARQ – a multi-view 3D object detector with transformer and pixel-aligned recurrent queries. Unlike previous works that use learnable features or only encode 3D point positions as queries in the decoder, PARQ leverages appearance-enhanced queries initialized from reference points in 3D space and updates their 3D location with recurrent cross-attention operations. Incorporating pixel-aligned features and cross attention enables the model to encode the necessary 3D-to-2D correspondences and capture global contextual information of the input images. PARQ outperforms prior best methods on the ScanNet and ARKitScenes datasets, learns and detects faster, is more robust to distribution shifts in reference points, can leverage additional input views without retraining, and can adapt inference compute by changing the number of recurrent iterations.
Skill Transformer: A Monolithic Policy for Mobile Manipulation
Xiaoyu Huang (Georgia Institute of Technology)*; Dhruv Batra (Georgia Tech & Facebook AI Research); Akshara Rai (Facebook); Andrew Szot (Georgia Institute of Technology)
We present Skill Transformer, an approach for solving long-horizon robotic tasks by combining conditional sequence modeling and skill modularity. Conditioned on egocentric and proprioceptive observations of a robot, Skill Transformer is trained end-to-end to predict both a high-level skill (e.g., navigation, picking, placing), and a whole-body low-level action (e.g., base and arm motion), using a transformer architecture and demonstration trajectories that solve the full task. It retains the composability and modularity of the overall task through a skill predictor module while reasoning about low-level actions and avoiding hand-off errors, common in modular approaches. We test Skill Transformer on an embodied rearrangement benchmark and find it performs robust task planning and low-level control in new scenarios, achieving a 2.5x higher success rate than baselines in hard rearrangement problems.
WDiscOOD: Out-of-Distribution Detection via Whitened Linear Discriminant Analysis
Yiye Chen (Georgia Institute of Technology)*; Yunzhi Lin (Georgia Institute of Technology); Ruinian Xu (Georgia Institute of Technology); Patricio A Vela (Georgia Institute of Technology)
Deep neural networks are susceptible to generating overconfident yet erroneous predictions when presented with data beyond known concepts. This challenge underscores the importance of detecting out-of-distribution (OOD) samples in the open world. In this work, we propose a novel feature-space OOD detection score based on class-specific and class-agnostic information. Specifically, the approach utilizes Whitened Linear Discriminant Analysis to project features into two subspaces – the discriminative and residual subspaces – for which the in-distribution (ID) classes are maximally separated and closely clustered, respectively. The OOD score is then determined by combining the deviation from the input data to the ID pattern in both subspaces. The efficacy of our method, named WDiscOOD, is verified on the large-scale ImageNet-1k benchmark, with six OOD datasets that cover a variety of distribution shifts. WDiscOOD demonstrates superior performance on deep classifiers with diverse backbone architectures, including CNN and vision transformer. Furthermore, we also show that WDiscOOD more effectively detects novel concepts in representation spaces trained with contrastive objectives, including supervised contrastive loss and multi-modality contrastive loss.
XNet: Wavelet-Based Low and High Frequency Fusion Networks for Fully- and Semi-Supervised Semantic Segmentation of Biomedical Images
Yanfeng Zhou (Institute of Automation, Chinese Academy of Sciences); Huang jiaxing (CASIA); Chenlong Wang (BioMap (Beijing) Intelligence Technology Limited); Le Song (Georgia Institute of Technology & Ant Financial); Ge Yang (National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences)*
Fully- and semi-supervised semantic segmentation of biomedical images have been advanced with the development of deep neural networks (DNNs). So far, however, DNN models are usually designed to support one of these two learning schemes, unified models that support both fully- and semi-supervised segmentation remain limited. Furthermore, few fully-supervised models focus on the intrinsic low frequency (LF) and high frequency (HF) information of images to improve performance. Perturbations in consistency-based semi-supervised models are often artificially designed. They may introduce negative learning bias that are not beneficial for training. In this study, we propose a wavelet-based LF and HF fusion model XNet, which supports both fully- and semi-supervised semantic segmentation and outperforms state-of-the-art models in both fields. It emphasizes extracting LF and HF information for consistency training to alleviate the learning bias caused by artificial perturbations. Extensive experiments on two 2D and two 3D datasets demonstrate the effectiveness of our model. Code is available at https://github.com/Yanfeng-Zhou/XNet.
Development: College of Computing, Machine Learning Center
Project and Web Lead: Joshua Preston
Data Interactive: Joshua Preston
Special Thanks to: ICCV Organizing Committee