NeurIPS 2023
The Conference on Neural Information Processing Systems (NeurIPS) is a venue at the forefront of research innovation in machine learning and artificial intelligence. NeurIPS 2023 — taking place Dec. 10-16 in New Orleans — includes more than 13,000 researchers in the main program.
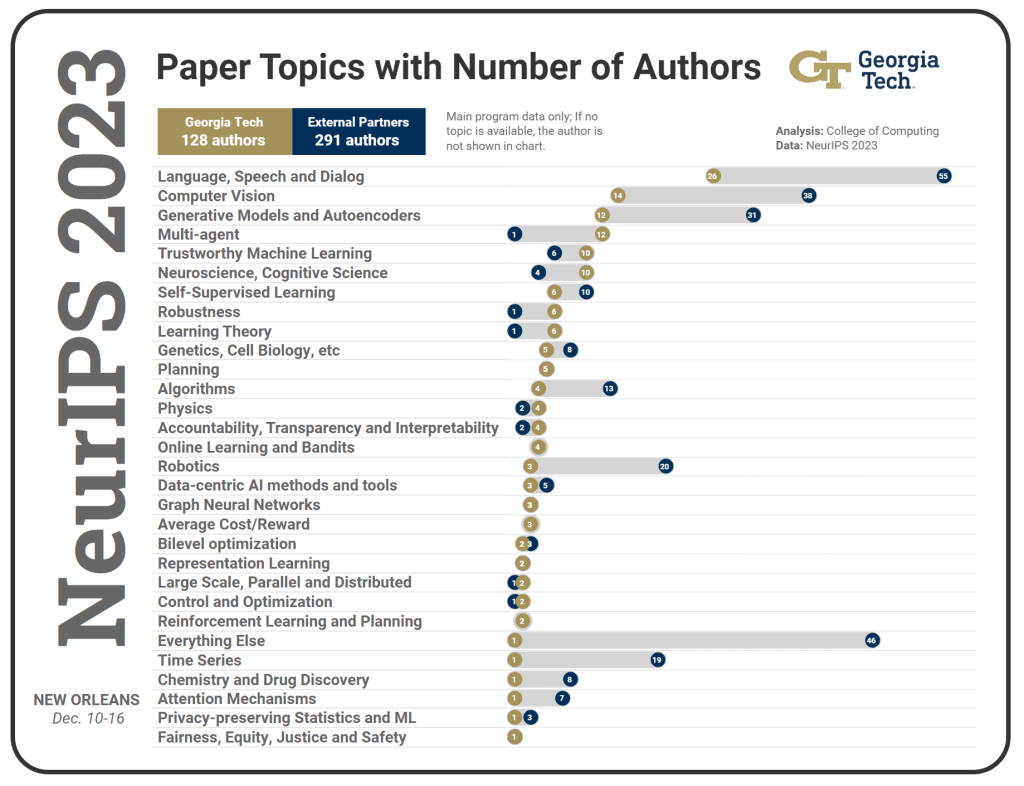
The international group of researchers, practitioners, and industry experts will introduce work across more than 85 topics in ML and AI. This year’s top areas (by number of main program papers) include computer vision, generative models and autoencoders, graph neural networks, learning theory, robustness, and neuroscience and cognitive science.
Explore Georgia Tech’s wholistic approach at NeurIPS to advancing machine learning and AI technologies that can be applied safely and ethically to advance society.
Georgia Tech @ NeurIPS 2023
Georgia Tech’s contributions at NeurIPS represent a wide range of machine learning innovations and where AI technology is making an impact in different parts of society. Our experts’ goals include implementing solutions that will safely advance our modern digital infrastructures and allow people to be secure in their work and leisure in an ever-changing world. Explore Georgia Tech’s work at NeurIPS to see how our experts are improving the human condition through technological innovation.
HOW TO READ:
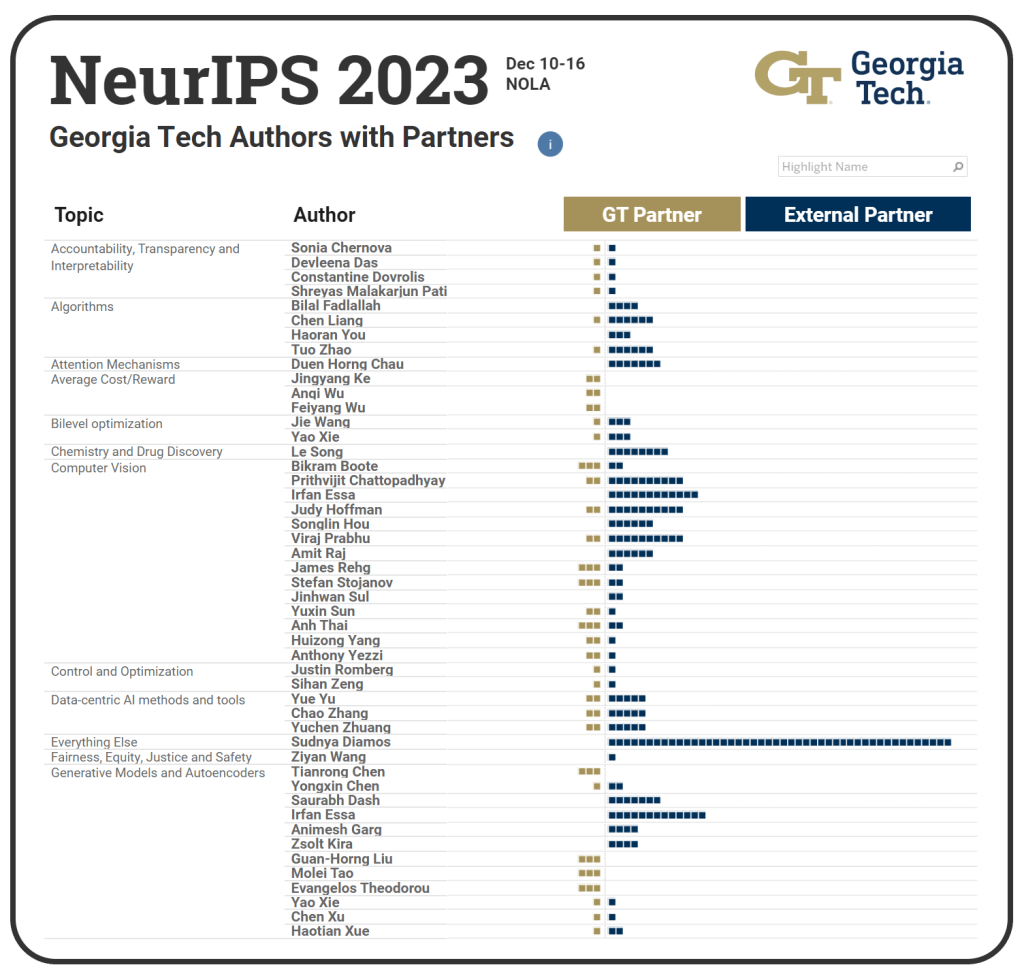
- Gold dots show the number of Georgia Tech authors. Blue dots are external partners.
- Topics are sorted by number of Georgia Tech authors (gold dots) in descending order.
NeurIPS Numbers
People
Faculty in the main program are pictured

Jacob Abernethy
Asst. Professor, Computer Science

Dhruv Batra
Assoc. Professor, Interactive Computing

Ümit Çatalyürek
Professor, Computational Science and Engineering

Duen Horng Chau
Assoc. Professor, Computational Science and Engineering

Yongxin Chen
Assoc. Professor, Aerospace Engineering

Sonia Chernova
Assoc. Professor, Interactive Computing

Bo Dai
Asst. Professor, Computational Science and Engineering

Mark Davenport
Professor, Electrical and Computer Engineering

Constantine Dovrolis
Professor, Computer Science

Eva Dyer
Assoc. Professor, Biomedical Engineering

Irfan Essa
Professor, Interactive Computing

Animesh Garg
Asst. Professor, Interactive Computing

Matthew Gombolay
Asst. Professor, Interactive Computing

Judy Hoffman
Asst. Professor, Interactive Computing

Zsolt Kira
Asst. Professor, Interactive Computing

Pan Li
Asst. Professor, Electrical and Computer Engineering

Celine Lin
Assoc. Professor, Computer Science

Ling Liu
Professor, Computer Science

Divya Mahajan
Asst. Professor, Electrical and Computer Engineering

Vidya Muthukumar
Asst. Professor, Electrical and Computer Engineering

Ashwin Pananjady
Asst. Professor, Industrial and Systems Engineering

Rampi Ramprasad
Professor, Materials Science and Engineering

Justin Romberg
Professor, Electrical and Computer Engineering

Humphrey Shi
Assoc. Professor, Interactive Computing

Thad Starner
Professor, Interactive Computing

Molei Tao
Assoc. Professor, Mathematics

Evangelos Theodorou
Assoc. Professor, Aerospace Engineering

Huan Tran
Senior Research Scientist, Materials Science and Engineering

Santosh Vempala
Professor, Computer Science

Jingyan Wang
Postdoctoral Fellow, Industrial and Systems Engineering

Anqi Wu
Asst. Professor, Computational Science and Engineering

Yao Xie
Professor, Industrial and Systems Engineering

Anthony Yezzi
Professor, Electrical and Computer Engineering

Chao Zhang
Asst. Professor, Computational Science and Engineering

Tuo Zhao
Asst. Professor, Industrial and Systems Engineering

Enlu Zhou
Assoc. Professor, Industrial and Systems Engineering

Saman Zonouz
Assoc. Professor, Cybersecurity and Privacy/Electrical and Computer Engineering
Students
Nauman Ahad • Vinam Arora • Mehdi Azabou • Muhammed Fatih Balin • Khushi Bhardwaj • Alexander Bukharin • Xinyuan Cao • Prithvijit Chattopadhyay • Binghong Chen • Tianrong Chen • Christopher Cui • Devleena Das • Gururaj Deshpande • Rui Feng • Venkataramana Ganesh • Jocelyn Heath • Sihao Hu • Zihao Hu • Tiansheng Huang • Yinan Huang • Fatih Ilhan • Yash Jain • Jihui Jin • Jingyang Ke • Lingkai Kong • Unnathi Kumar • Tyler Kwok • Tyler LaBonte • Chengrui Li • Yan Li • Chen Liang • Guan-Horng Liu • Yen-Cheng Liu • Arjun Majumdar • Shreyas Malakarjun Patil • David Martin • Matthew McKinley • Michael Mendelson • Priyanka Mosur • Santosh Nachimuthu • Bill Neubauer • Viraj Prabhu • Caleb Robinson • Daniel Scott • Daksh Sehgal • Rajandeep Singh • James S Smith • Matthew So • Maks Sorokin • Rohit Sridhar • Stefan Stojanov • Jinhwan Sul • Haotian Sun • Yuxin Sun • Alec Tan • Selim Tekin • Anh Thai • Junjiao Tian • Aubrey Toland • Sofia Vempala • Guanghui Wang • Irene Wang • Jie Wang • Kuan Wang • Yuhao Wang • Yule Wang • Ziyan Wang • Feiyang Wu • Zijing Wu • Jerry Xiong • Austin Xu • Chen Xu • Haotian Xue • Huizong Yang • Sriram Yenamandra • Haoran You • Yue Yu • Qingru Zhang • Yuchen Zhuang
Alumni
Bikram Boote • Glenn Cameron • Zhehui Chen • Saurabh Dash • Sudnya Diamos • Mehrdad Ghadiri • Songlin Hou • Haoming Jiang • Sanjay Kariyappa • Etienne Ollivier • Amit Raj • Heather Rocker • Mariah Schrum • Esmaeil Seraj • Sahir Shahryar • Jingfeng Yang • Sihan Zeng • Simiao Zuo


Stress Test Method Detects When Object Recognition Models are Using Shortcuts
By Nathan Deen
A new “stress test” method created by a Georgia Tech researcher allows programmers to more easily determine if trained visual recognition models are sensitive to input changes or rely too heavily on context clues to perform their tasks.
Viraj Prabhu, a Ph.D. student in Georgia Tech’s School of Interactive Computing, introduced the LANCE (Language-Guided Counterfactuals) method in a recent research paper that shows how deep object recognition models are prone to taking shortcuts through context clues to produce images.
Ideally, models should understand exactly what they’re prompted to search for, Prabhu said, but because of spurious correlation, they tend to use irrelevant information in images as they make predictions.
Prabhu used LANCE to stress test well-known models that have been trained on the image database ImageNet. Working with Assistant Professor Judy Hoffman and co-authors Sriram Yenamandra and Prithvijit Chattopadhyay, he discovered many instances in which the models were overly reliant on context in the images they produced.

When a model is getting something right, is it getting it right because it really understands it, or is it picking up on some context clues and relying on them? There is no reason why it should be relying on what kind of vehicle it is to know whether there is a seatbelt, but models often do this. It’s more generally known as model bias or a spurious correlation problem.
Viraj Prabhu, Ph.D. student, School of Interactive Computing

Photo by JP Popham
iLeakage shows these attacks are still relevant and exploitable, even after nearly six years of Spectre mitigation efforts following its discovery. Spectre attacks coerce CPUs into speculatively executing the wrong flow of instructions. We have found that this can be used in several different environments, including Google Chrome and Safari.
Daniel Genkin, Assoc. Professor, Cybersecurity and Privacy/Computer Science
Researchers Break Apple’s New MacBook Pro Weeks After Release
By John “JP” Popham
A researcher from Georgia Tech demonstrated how to slip past security measures on Apple’s latest MacBook Pro with the M3 processor chip to capture the Facebook password and second factor authentication text of his fictional target.
By the end of his demonstration video, Ph.D. student Jason Kim showed how the recently discovered iLeakage side-channel exploit is still a genuine threat to Apple devices, regardless of how updated their software might be.
First discovered by Kim and Daniel Genkin, an associate professor in the School of Cybersecurity and Privacy, the vulnerability affects all recent iPhones, iPads, laptops, and desktops produced by Apple since 2020.
iLeakage allows attackers to see what’s happening on their target’s Safari browser. This vulnerability allows potential access to Instagram login credentials, Gmail inboxes, and YouTube watch histories, as Kim demonstrated last month on a slightly older MacBook Pro.
Schedule
NOV 27
11:30 a.m.
Hardware, Side Channels, and CyberPhysical Systems
Side-channels
Optical Cryptanalysis: Recovering Cryptographic Keys from Power LED Light Fluctuations
NOV 28
1:45 p.m.
Blockchain and Distributed Systems
Interoperability & 2nd layer solutions
CryptoConcurrency: [Almost] Consensusless Asset Transfer with Shared Accounts
2 p.m.
Applied Cryptography
Zero Knowledge Proofs
Batchman and Robin: Batched and Non-batched Branching for Interactive ZK
3:15 p.m.
Hardware, Side Channels, and CyberPhysical Systems
Speculative execution & information flow
iLeakage: Browser-based Timerless Speculative Execution Attacks on Apple Devices
NOV 29
9:30 a.m.
Security Usability and Measurement
Measuring Security Deployments
Evaluating the Security Posture of Real-World FIDO2 Deployments
11:15 a.m.
Applied Cryptography
Multiparty Computation II
Towards Generic MPC Compilers via Variable Instruction Set Architectures [VISAs]
11:15 a.m.
Software Security
Program Analysis & Instrumentation
Improving Security Tasks Using Compiler Provenance Information Recovered At the Binary-Level
1:30 p.m.
Security Usability and Measurement
Usable Authentication
Measuring Website Password Creation Policies At Scale
Big Picture
Explore all main program topics by number of total paper acceptances at NeurIPS 2023. Use the search option to find organizations contributing to a topic; select only one keyword in the org name for best results. The default view shows the “georgia” keyword, which displays topics where the “georgia” organization(s) is contributing.

Research
Main Program Papers only*
Accountability, Transparency and Interpretability
Shreyas Malakarjun Patil, Loizos Michael, Constantine Dovrolis
Natural target functions and tasks typically exhibit hierarchical modularity — they can be broken down into simpler sub-functions that are organized in a hierarchy. Such sub-functions have two important features: they have a distinct set of inputs (input-separability) and they are reused as inputs higher in the hierarchy (reusability). Previous studies have established that hierarchically modular neural networks, which are inherently sparse, offer benefits such as learning efficiency, generalization, multi-task learning, and transfer. However, identifying the underlying sub-functions and their hierarchical structure for a given task can be challenging. The high-level question in this work is: if we learn a task using a sufficiently deep neural network, how can we uncover the underlying hierarchy of sub-functions in that task? As a starting point, we examine the domain of Boolean functions, where it is easier to determine whether a task is hierarchically modular. We propose an approach based on iterative unit and edge pruning (during training), combined with network analysis for module detection and hierarchy inference. Finally, we demonstrate that this method can uncover the hierarchical modularity of a wide range of Boolean functions and two vision tasks based on the MNIST digits dataset.
State2Explanation: Concept-Based Explanations to Benefit Agent Learning and User Understanding
Devleena Das, Sonia Chernova, Been Kim
As more non-AI experts use complex AI systems for daily tasks, there has been an increasing effort to develop methods that produce explanations of AI decision making that are understandable by non-AI experts. Towards this effort, leveraging higher-level concepts and producing concept-based explanations have become a popular method. Most concept-based explanations have been developed for classification techniques, and we posit that the few existing methods for sequential decision making are limited in scope. In this work, we first contribute a desiderata for defining “concepts” in sequential decision making settings. Additionally, inspired by the Protege Effect which states explaining knowledge often reinforces one’s self-learning, we explore how concept-based explanations of an RL agent’s decision making can in turn improve the agent’s learning rate, as well as improve end-user understanding of the agent’s decision making. To this end, we contribute a unified framework, State2Explanation (S2E), that involves learning a joint embedding model between state-action pairs and concept-based explanations, and leveraging such learned model to both (1) inform reward shaping during an agent’s training, and (2) provide explanations to end-users at deployment for improved task performance. Our experimental validations, in Connect 4 and Lunar Lander, demonstrate the success of S2E in providing a dual-benefit, successfully informing reward shaping and improving agent learning rate, as well as significantly improving end user task performance at deployment time.
Algorithms
An Inductive Bias for Tabular Deep Learning
Ege Beyazit, Jonathan Kozaczuk, Bo Li, Vanessa Wallace, Bilal Fadlallah
Deep learning methods have achieved state-of-the-art performance in most modeling tasks involving images, text and audio, however, they typically underperform tree-based methods on tabular data. In this paper, we hypothesize that a significant contributor to this performance gap is the interaction between irregular target functions resulting from the heterogeneous nature of tabular feature spaces, and the well-known tendency of neural networks to learn smooth functions. Utilizing tools from spectral analysis, we show that functions described by tabular datasets often have high irregularity, and that they can be smoothed by transformations such as scaling and ranking in order to improve performance. However, because these transformations tend to lose information or negatively impact the loss landscape during optimization, they need to be rigorously fine-tuned for each feature to achieve performance gains. To address these problems, we propose introducing frequency reduction as an inductive bias. We realize this bias as a neural network layer that promotes learning low-frequency representations of the input features, allowing the network to operate in a space where the target function is more regular. Our proposed method introduces less computational complexity than a fully connected layer, while significantly improving neural network performance, and speeding up its convergence on 14 tabular datasets.
Module-wise Adaptive Distillation for Multimodality Foundation Models
Chen Liang, Jiahui Yu, Ming-Hsuan Yang, Matthew Brown, Yin Cui, Tuo Zhao, Boqing Gong, Tianyi Zhou
Pre-trained multimodal foundation models have demonstrated remarkable generalizability but pose challenges for deployment due to their large sizes. One effective approach to reducing their sizes is layerwise distillation, wherein small student models are trained to match the hidden representations of large teacher models at each layer. Motivated by our observation that certain architecture components, referred to as modules, contribute more significantly to the student’s performance than others, we propose to track the contributions of individual modules by recording the loss decrement after distillation each module and choose the module with a greater contribution to distill more frequently. Such an approach can be naturally formulated as a multi-armed bandit (MAB) problem, where modules and loss decrements are considered as arms and rewards, respectively. We then develop a modified-Thompson sampling algorithm named OPTIMA to address the nonstationarity of module contributions resulting from model updating. Specifically, we leverage the observed contributions in recent history to estimate the changing contribution of each module and select modules based on these estimations to maximize the cumulative contribution. We evaluate the effectiveness of OPTIMA through distillation experiments on various multimodal understanding and image captioning tasks, using the CoCa-Large model \citep{yu2022coca} as the teacher model.
ShiftAddViT: Mixture of Multiplication Primitives Towards Efficient Vision Transformer
Haoran You, Huihong Shi, Yipin Guo, Celine Lin
Vision Transformers (ViTs) have shown impressive performance and have become a unified backbone for multiple vision tasks. However, both the attention mechanism and multi-layer perceptrons (MLPs) in ViTs are not sufficiently efficient due to dense multiplications, leading to costly training and inference. To this end, we propose to reparameterize pre-trained ViTs with a mixture of multiplication primitives, e.g., bitwise shifts and additions, towards a new type of multiplication-reduced model, dubbed $\textbf{ShiftAddViT}$, which aims to achieve end-to-end inference speedups on GPUs without requiring training from scratch. Specifically, all $\texttt{MatMuls}$ among queries, keys, and values are reparameterized using additive kernels, after mapping queries and keys to binary codes in Hamming space. The remaining MLPs or linear layers are then reparameterized with shift kernels. We utilize TVM to implement and optimize those customized kernels for practical hardware deployment on GPUs. We find that such a reparameterization on (quadratic or linear) attention maintains model accuracy, while inevitably leading to accuracy drops when being applied to MLPs. To marry the best of both worlds, we further propose a new mixture of experts (MoE) framework to reparameterize MLPs by taking multiplication or its primitives as experts, e.g., multiplication and shift, and designing a new latency-aware load-balancing loss. Such a loss helps to train a generic router for assigning a dynamic amount of input tokens to different experts according to their latency. In principle, the faster the experts run, the more input tokens they are assigned. Extensive experiments on various 2D/3D Transformer-based vision tasks consistently validate the effectiveness of our proposed ShiftAddViT, achieving up to $\textbf{5.18$\times$}$ latency reductions on GPUs and $\textbf{42.9}$% energy savings, while maintaining a comparable accuracy as original or efficient ViTs. Codes and models are available at https://github.com/GATECH-EIC/ShiftAddViT.
Attention Mechanisms
Benjamin Hoover, Yuchen Liang, Bao Pham, Rameswar Panda, Hendrik Strobelt, Duen Horng Chau, Mohammed Zaki, Dmitry Krotov
Our work combines aspects of three promising paradigms in machine learning, namely, attention mechanism, energy-based models, and associative memory. Attention is the power-house driving modern deep learning successes, but it lacks clear theoretical foundations. Energy-based models allow a principled approach to discriminative and generative tasks, but the design of the energy functional is not straightforward. At the same time, Dense Associative Memory models or Modern Hopfield Networks have a well-established theoretical foundation, and allow an intuitive design of the energy function. We propose a novel architecture, called the Energy Transformer (or ET for short), that uses a sequence of attention layers that are purposely designed to minimize a specifically engineered energy function, which is responsible for representing the relationships between the tokens. In this work, we introduce the theoretical foundations of ET, explore its empirical capabilities using the image completion task, and obtain strong quantitative results on the graph anomaly detection and graph classification tasks.
Average Cost/Reward
Inverse Reinforcement Learning with the Average Reward Criterion
Feiyang Wu, Jingyang Ke, Anqi Wu
We study the problem of Inverse Reinforcement Learning (IRL) with an average-reward criterion. The goal is to recover an unknown policy and a reward function when the agent only has samples of states and actions from an experienced agent. Previous IRL methods assume that the expert is trained in a discounted environment, and the discount factor is known. This work alleviates this assumption by proposing an average-reward framework with efficient learning algorithms. We develop novel stochastic first-order methods to solve the IRL problem under the average-reward setting, which requires solving an Average-reward Markov Decision Process (AMDP) as a subproblem. To solve the subproblem, we develop a Stochastic Policy Mirror Descent (SPMD) method under general state and action spaces that needs $\mathcal{O}(1/\varepsilon)$ steps of gradient computation. Equipped with SPMD, we propose the Inverse Policy Mirror Descent (IPMD) method for solving the IRL problem with a $\mathcal{O}(1/\varepsilon^2)$ complexity. To the best of our knowledge, the aforementioned complexity results are new in IRL with the average reward criterion. Finally, we corroborate our analysis with numerical experiments using the MuJoCo benchmark and additional control tasks.
Bilevel optimization
Contextual Stochastic Bilevel Optimization
Yifan Hu, Jie Wang, Yao Xie, Andreas Krause, Daniel Kuhn
We introduce contextual stochastic bilevel optimization (CSBO) — a stochastic bilevel optimization framework with the lower-level problem minimizing an expectation conditioned on some contextual information and the upper-level decision variable. This framework extends classical stochastic bilevel optimization when the lower-level decision maker responds optimally not only to the decision of the upper-level decision maker but also to some side information and when there are multiple or even infinite many followers. It captures important applications such as meta-learning, personalized federated learning, end-to-end learning, and Wasserstein distributionally robust optimization with side information (WDRO-SI). Due to the presence of contextual information, existing single-loop methods for classical stochastic bilevel optimization are unable to converge. To overcome this challenge, we introduce an efficient double-loop gradient method based on the Multilevel Monte-Carlo (MLMC) technique and establish its sample and computational complexities. When specialized to stochastic nonconvex optimization, our method matches existing lower bounds. For meta-learning, the complexity of our method does not depend on the number of tasks. Numerical experiments further validate our theoretical results.
Chemistry and Drug Discovery
Injecting Multimodal Information into Rigid Protein Docking via Bi-level Optimization
Ruijia Wang, YiWu Sun, Yujie Luo, Shaochuan Li, Cheng Yang, Xingyi Cheng, Hui Li, Chuan Shi, Le Song
The structure of protein-protein complexes is critical for understanding binding dynamics, biological mechanisms, and intervention strategies. Rigid protein docking, a fundamental problem in this field, aims to predict the 3D structure of complexes from their unbound states without conformational changes. In this scenario, we have access to two types of valuable information: sequence-modal information, such as coevolutionary data obtained from multiple sequence alignments, and structure-modal information, including the 3D conformations of rigid structures. However, existing docking methods typically utilize single-modal information, resulting in suboptimal predictions. In this paper, we propose xTrimoBiDock (or BiDock for short), a novel rigid docking model that effectively integrates sequence- and structure-modal information through bi-level optimization. Specifically, a cross-modal transformer combines multimodal information to predict an inter-protein distance map. To achieve rigid docking, the roto-translation transformation is optimized to align the docked pose with the predicted distance map. In order to tackle this bi-level optimization problem, we unroll the gradient descent of the inner loop and further derive a better initialization for roto-translation transformation based on spectral estimation. Compared to baselines, BiDock achieves a promising result of a maximum 234% relative improvement in challenging antibody-antigen docking problem.
Computer Vision
ARTIC3D: Learning Robust Articulated 3D Shapes from Noisy Web Image Collections
Chun-Han Yao, Amit Raj, Wei-Chih Hung, Michael Rubinstein, Yuanzhen Li, Ming-Hsuan Yang, Varun Jampani
Estimating 3D articulated shapes like animal bodies from monocular images is inherently challenging due to the ambiguities of camera viewpoint, pose, texture, lighting, etc. We propose ARTIC3D, a self-supervised framework to reconstruct per-instance 3D shapes from a sparse image collection in-the-wild. Specifically, ARTIC3D is built upon a skeleton-based surface representation and is further guided by 2D diffusion priors from Stable Diffusion. First, we enhance the input images with occlusions/truncation via 2D diffusion to obtain cleaner mask estimates and semantic features. Second, we perform diffusion-guided 3D optimization to estimate shape and texture that are of high-fidelity and faithful to input images. We also propose a novel technique to calculate more stable image-level gradients via diffusion models compared to existing alternatives. Finally, we produce realistic animations by fine-tuning the rendered shape and texture under rigid part transformations. Extensive evaluations on multiple existing datasets as well as newly introduced noisy web image collections with occlusions and truncation demonstrate that ARTIC3D outputs are more robust to noisy images, higher quality in terms of shape and texture details, and more realistic when animated.
Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
Micah Goldblum, Hossein Souri, Renkun Ni, Manli Shu, Viraj Prabhu, Gowthami Somepalli, Prithvijit Chattopadhyay, Mark Ibrahim, Adrien Bardes, Judy Hoffman, Rama Chellappa, Andrew Wilson, Tom Goldstein
Neural network based computer vision systems are typically built on a backbone, a pretrained or randomly initialized feature extractor. Several years ago, the default option was an ImageNet-trained convolutional neural network. However, the recent past has seen the emergence of countless backbones pretrained using various algorithms and datasets. While this abundance of choice has led to performance increases for a range of systems, it is difficult for practitioners to make informed decisions about which backbone to choose. Battle of the Backbones (BoB) makes this choice easier by benchmarking a diverse suite of pretrained models, including vision-language models, those trained via self-supervised learning, and the Stable Diffusion backbone, across a diverse set of computer vision tasks ranging from classification to object detection to OOD generalization and more. Furthermore, BoB sheds light on promising directions for the research community to advance computer vision by illuminating strengths and weakness of existing approaches through a comprehensive analysis conducted on more than 1500 training runs. While vision transformers (ViTs) and self-supervised learning (SSL) are increasingly popular, we find that convolutional neural networks pretrained in a supervised fashion on large training sets still perform best on most tasks among the models we consider. Moreover, in apples-to-apples comparisons on the same architectures and similarly sized pretraining datasets, we find that SSL backbones are highly competitive, indicating that future works should perform SSL pretraining with advanced architectures and larger pretraining datasets. We release the raw results of our experiments along with code that allows researchers to put their own backbones through the gauntlet here: https://github.com/hsouri/Battle-of-the-Backbones.
InfoCD: A Contrastive Chamfer Distance Loss for Point Cloud Completion
Fangzhou Lin, Yun Yue, Ziming Zhang, Songlin Hou, Kazunori Yamada, Vijaya Kolachalama, Venkatesh Saligrama
A point cloud is a discrete set of data points sampled from a 3D geometric surface. Chamfer distance (CD) is a popular metric and training loss to measure the distances between point clouds, but also well known to be sensitive to outliers. To address this issue, in this paper we propose InfoCD, a novel contrastive Chamfer distance loss to learn to spread the matched points for better distribution alignments between point clouds as well as accounting for a surface similarity estimator. We show that minimizing InfoCD is equivalent to maximizing a lower bound of the mutual information between the underlying geometric surfaces represented by the point clouds, leading to a regularized CD metric which is robust and computationally efficient for deep learning. We conduct comprehensive experiments for point cloud completion using InfoCD and observe significant improvements consistently over all the popular baseline networks trained with CD-based losses, leading to new state-of-the-art results on several benchmark datasets. Demo code is available at https://github.com/Zhang-VISLab/NeurIPS2023-InfoCD.
Learning Mask-aware CLIP Representations for Zero-Shot Segmentation
Siyu Jiao, Yunchao Wei, Yaowei Wang, Yao Zhao, Humphrey Shi
Recently, pre-trained vision-language models have been increasingly used to tackle the challenging zero-shot segmentation task. Typical solutions follow the paradigm of first generating mask proposals and then adopting CLIP to classify them. To maintain the CLIP’s zero-shot transferability, previous practices favour to freeze CLIP during training. However, in the paper, we reveal that CLIP is insensitive to different mask proposals and tends to produce similar predictions for various mask proposals of the same image. This insensitivity results in numerous false positives when classifying mask proposals. This issue mainly relates to the fact that CLIP is trained with image-level supervision. To alleviate this issue, we propose a simple yet effective method, named Mask-aware Fine-tuning (MAFT). Specifically, Image-Proposals CLIP Encoder (IP-CLIP Encoder) is proposed to handle arbitrary numbers of image and mask proposals simultaneously. Then, mask-aware loss and self-distillation loss are designed to fine-tune IP-CLIP Encoder, ensuring CLIP is responsive to different mask proposals while not sacrificing transferability. In this way, mask-aware representations can be easily learned to make the true positives stand out. Notably, our solution can seamlessly plug into most existing methods without introducing any new parameters during the fine-tuning process. We conduct extensive experiments on the popular zero-shot benchmarks. With MAFT, the performance of the state-of-the-art methods is promoted by a large margin: 50.4% (+ 8.2%) on COCO, 81.8% (+ 3.2%) on Pascal-VOC, and 8.7% (+4.3%) on ADE20K in terms of mIoU for unseen classes. Codes will be provided for reproducibility. Code is available at https://github.com/jiaosiyu1999/MAFT.git .
Low-shot Object Learning with Mutual Exclusivity Bias
Anh Thai, Ahmad Humayun, Stefan Stojanov, Zixuan Huang, Bikram Boote, James Rehg
This paper introduces Low-shot Object Learning with Mutual Exclusivity Bias (LSME), the first computational framing of mutual exclusivity bias, a phenomenon commonly observed in infants during word learning. We provide a novel dataset, comprehensive baselines, and a SOTA method to enable the ML community to tackle this challenging learning task. The goal of LSME is to analyze an RGB image of a scene containing multiple objects and correctly associate a previously-unknown object instance with a provided category label. This association is then used to perform low-shot learning to test category generalization. We provide a data generation pipeline for the LSME problem and conduct a thorough analysis of the factors that contribute to its difficulty. Additionally, we evaluate the performance of multiple baselines, including state-of-the-art foundation models. Finally, we present a baseline approach that outperforms state-of-the-art models in terms of low-shot accuracy. Code and data are available at https://github.com/rehg-lab/LSME.
Mr. HiSum: A Large-scale Dataset for Video Highlight Detection and Summarization
Jinhwan Sul, Jihoon Han, Joonseok Lee
Video highlight detection is a task to automatically select the most engaging moments from a long video. This problem is highly challenging since it aims to learn a general way of finding highlights from a variety of videos in the real world.The task has an innate subjectivity because the definition of a highlight differs across individuals. Therefore, to detect consistent and meaningful highlights, prior benchmark datasets have been labeled by multiple (5-20) raters. Due to the high cost of manual labeling, most existing public benchmarks are in extremely small scale, containing only a few tens or hundreds of videos. This insufficient benchmark scale causes multiple issues such as unstable evaluation or high sensitivity in traintest splits. We present Mr. HiSum, a large-scale dataset for video highlight detection and summarization, containing 31,892 videos and reliable labels aggregated over 50,000+ users per video. We empirically prove reliability of the labels as frame importance by cross-dataset transfer and user study.
SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs
Lijun Yu, Yong Cheng, Zhiruo Wang, Vivek Kumar, Wolfgang Macherey, Yanping Huang, David Ross, Irfan Essa, Yonatan Bisk, Ming-Hsuan Yang, Kevin Murphy, Alexander Hauptmann, Lu Jiang
In this work, we introduce Semantic Pyramid AutoEncoder (SPAE) for enabling frozen LLMs to perform both understanding and generation tasks involving non-linguistic modalities such as images or videos. SPAE converts between raw pixels and interpretable lexical tokens (or words) extracted from the LLM’s vocabulary. The resulting tokens capture both the rich semantic meaning and the fine-grained details needed for visual reconstruction, effectively translating the visual content into a language comprehensible to the LLM, and empowering it to perform a wide array of multimodal tasks. Our approach is validated through in-context learning experiments with frozen PaLM 2 and GPT 3.5 on a diverse set of image understanding and generation tasks.Our method marks the first successful attempt to enable a frozen LLM to generate image content while surpassing state-of-the-art performance in image understanding tasks, under the same setting, by over 25%.
Stabilizing the Optimization of Neural Signed Distance Functions and Finer Shape Representation
Huizong Yang, Yuxin Sun, Ganesh Sundaramoorthi, Anthony Yezzi
We present new insights and a novel paradigm for learning implicit neural representations (INR) of shapes. In particular, we shed light on the popular eikonal loss used for imposing a signed distance function constraint in INR. We show analytically that as the representation power of the network increases, the optimization approaches a partial differential equation (PDE) in the continuum limit that is unstable. We show that this instability can manifest in existing network optimization, leading to irregularities in the reconstructed surface and/or convergence to sub-optimal local minima, and thus fails to capture fine geometric and topological structure. We show analytically how other terms added to the loss, currently used in the literature for other purposes, can actually eliminate these instabilities. However, such terms can over-regularize the surface, preventing the representation of fine shape detail. Based on a similar PDE theory for the continuum limit, we introduce a new regularization term that still counteracts the eikonal instability but without over-regularizing. Furthermore, since stability is now guaranteed in the continuum limit, this stabilization also allows for considering new network structures that are able to represent finer shape detail. We introduce such a structure based on quadratic layers. Experiments on multiple benchmark data sets show that our new regularization and network are able to capture more precise shape details and more accurate topology than existing state-of-the-art.
Control and Optimization
Connected Superlevel Set in (Deep) Reinforcement Learning and its Application to Minimax Theorems
Sihan Zeng, Thinh Doan, Justin Romberg
The aim of this paper is to improve the understanding of the optimization landscape for policy optimization problems in reinforcement learning. Specifically, we show that the superlevel set of the objective function with respect to the policy parameter is always a connected set both in the tabular setting and under policies represented by a class of neural networks. In addition, we show that the optimization objective as a function of the policy parameter and reward satisfies a stronger “equiconnectedness” property. To our best knowledge, these are novel and previously unknown discoveries.We present an application of the connectedness of these superlevel sets to the derivation of minimax theorems for robust reinforcement learning. We show that any minimax optimization program which is convex on one side and is equiconnected on the other side observes the minimax equality (i.e. has a Nash equilibrium). We find that this exact structure is exhibited by an interesting class of robust reinforcement learning problems under an adversarial reward attack, and the validity of its minimax equality immediately follows. This is the first time such a result is established in the literature.
Data-centric AI methods and tools
Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias
Yue Yu, Yuchen Zhuang, Jieyu Zhang, Yu Meng, Alexander Ratner, Ranjay Krishna, Jiaming Shen, Chao Zhang
Large language models (LLMs) have been recently leveraged as training data generators for various natural language processing (NLP) tasks. While previous research has explored different approaches to training models using generated data, they generally rely on simple class-conditional prompts, which may limit the diversity of the generated data and inherit systematic biases of LLM. Thus, we investigate training data generation with diversely attributed prompts (e.g., specifying attributes like length and style), which have the potential to yield diverse and attributed generated data. Our investigation focuses on datasets with high cardinality and diverse domains, wherein we demonstrate that attributed prompts outperform simple class-conditional prompts in terms of the resulting model’s performance. Additionally, we present a comprehensive empirical study on data generation encompassing vital aspects like bias, diversity, and efficiency, and highlight three key observations: firstly, synthetic datasets generated by simple prompts exhibit significant biases, such as regional bias; secondly, attribute diversity plays a pivotal role in enhancing model performance; lastly, attributed prompts achieve the performance of simple class-conditional prompts while utilizing only 5\% of the querying cost of ChatGPT associated with the latter. The data and code are available on {\url{https://github.com/yueyu1030/AttrPrompt}}.
Fairness, Equity, Justice and Safety
Variational Imbalanced Regression: Fair Uncertainty Quantification via Probabilistic Smoothing
Ziyan Wang, Hao Wang
Existing regression models tend to fall short in both accuracy and uncertainty estimation when the label distribution is imbalanced. In this paper, we propose a probabilistic deep learning model, dubbed variational imbalanced regression (VIR), which not only performs well in imbalanced regression but naturally produces reasonable uncertainty estimation as a byproduct. Different from typical variational autoencoders assuming I.I.D. representations (a data point’s representation is not directly affected by other data points), our VIR borrows data with similar regression labels to compute the latent representation’s variational distribution; furthermore, different from deterministic regression models producing point estimates, VIR predicts the entire normal-inverse-gamma distributions and modulates the associated conjugate distributions to impose probabilistic reweighting on the imbalanced data, thereby providing better uncertainty estimation. Experiments in several real-world datasets show that our VIR can outperform state-of-the-art imbalanced regression models in terms of both accuracy and uncertainty estimation. Code will soon be available at https://github.com/Wang-ML-Lab/variational-imbalanced-regression.
Functional Approximation
Ordering-based Conditions for Global Convergence of Policy Gradient Methods
Jincheng Mei, Bo Dai, Alekh Agarwal, Mohammad Ghavamzadeh, Csaba Szepesvari, Dale Schuurmans
We prove that, for finite-arm bandits with linear function approximation, the global convergence of policy gradient (PG) methods depends on inter-related properties between the policy update and the representation. textcolor{blue}{First}, we establish a few key observations that frame the study: \textbf{(i)} Global convergence can be achieved under linear function approximation without policy or reward realizability, both for the standard Softmax PG and natural policy gradient (NPG). \textbf{(ii)} Approximation error is not a key quantity for characterizing global convergence in either algorithm. \textbf{(iii)} The conditions on the representation that imply global convergence are different between these two algorithms. Overall, these observations call into question approximation error as an appropriate quantity for characterizing the global convergence of PG methods under linear function approximation. \textcolor{blue}{Second}, motivated by these observations, we establish new general results: \textbf{(i)} NPG with linear function approximation achieves global convergence \emph{if and only if} the projection of the reward onto the representable space preserves the optimal action’s rank, a quantity that is not strongly related to approximation error. \textbf{(ii)} The global convergence of Softmax PG occurs if the representation satisfies a non-domination condition and can preserve the ranking of rewards, which goes well beyond policy or reward realizability. We provide experimental results to support these theoretical findings.
Generative Models and Autoencoders
Diffusion-Based Adversarial Sample Generation for Improved Stealthiness and Controllability
Haotian Xue, Alexandre Araujo, Bin Hu, Yongxin Chen
Neural networks are known to be susceptible to adversarial samples: small variations of natural examples crafted to deliberatelymislead the models. While they can be easily generated using gradient-based techniques in digital and physical scenarios, they often differ greatly from the actual data distribution of natural images, resulting in a trade-off between strength and stealthiness. In this paper, we propose a novel framework dubbed Diffusion-Based Projected Gradient Descent (Diff-PGD) for generating realistic adversarial samples. By exploiting a gradient guided by a diffusion model, Diff-PGD ensures that adversarial samples remain close to the original data distribution while maintaining their effectiveness. Moreover, our framework can be easily customized for specific tasks such as digital attacks, physical-world attacks, and style-based attacks. Compared with existing methods for generating natural-style adversarial samples, our framework enables the separation of optimizing adversarial loss from other surrogate losses (e.g. content/smoothness/style loss), making it more stable and controllable. Finally, we demonstrate that the samples generated using Diff-PGD have better transferability and anti-purification power than traditional gradient-based methods.
Intriguing Properties of Quantization at Scale
Arash Ahmadian, Saurabh Dash, Hongyu Chen, Bharat Venkitesh, Zhen Stephen Gou, Phil Blunsom, Ahmet Üstün, Sara Hooker
Emergent properties have been widely adopted as a term to describe behavior not present in smaller models but observed in larger models (Wei et al., 2022a). Recent work suggests that the trade-off incurred by quantization is also an emergent property, with sharp drops in performance in models over 6B parameters. In this work, we ask _are quantization cliffs in performance solely a factor of scale?_ Against a backdrop of increased research focus on why certain emergent properties surface at scale, this work provides a useful counter-example. We posit that it is possible to optimize for a quantization friendly training recipe that suppresses large activation magnitude outliers. Here, we find that outlier dimensions are not an inherent product of scale, but rather sensitive to the optimization conditions present during pre-training. This both opens up directions for more efficient quantization, and poses the question of whether other emergent properties are inherent or can be altered and conditioned by optimization and architecture design choices. We successfully quantize models ranging in size from 410M to 52B with minimal degradation in performance.
Mirror Diffusion Models for Constrained and Watermarked Generation
Guan-Horng Liu, Tianrong Chen, Evangelos Theodorou, Molei Tao
Modern successes of diffusion models in learning complex, high-dimensional data distributions are attributed, in part, to their capability to construct diffusion processes with analytic transition kernels and score functions. The tractability results in a simulation-free framework with stable regression losses, from which reversed, generative processes can be learned at scale. However, when data is confined to a constrained set as opposed to a standard Euclidean space, these desirable characteristics appear to be lost based on prior attempts. In this work, we propose Mirror Diffusion Models (MDM), a new class of diffusion models that generate data on convex constrained sets without losing any tractability. This is achieved by learning diffusion processes in a dual space constructed from a mirror map, which, crucially, is a standard Euclidean space. We derive efficient computation of mirror maps for popular constrained sets, such as simplices and $\ell_2$-balls, showing significantly improved performance of MDM over existing methods. For safety and privacy purposes, we also explore constrained sets as a new mechanism to embed invisible but quantitative information (i.e., watermarks) in generated data, for which MDM serves as a compelling approach. Our work brings new algorithmic opportunities for learning tractable diffusion on complex domains.
Normalizing flow neural networks by JKO scheme
Chen Xu, Xiuyuan Cheng, Yao Xie
Normalizing flow is a class of deep generative models for efficient sampling and likelihood estimation, which achieves attractive performance, particularly in high dimensions. The flow is often implemented using a sequence of invertible residual blocks. Existing works adopt special network architectures and regularization of flow trajectories. In this paper, we develop a neural ODE flow network called JKO-iFlow, inspired by the Jordan-Kinderleherer-Otto (JKO) scheme, which unfolds the discrete-time dynamic of the Wasserstein gradient flow. The proposed method stacks residual blocks one after another, allowing efficient block-wise training of the residual blocks, avoiding sampling SDE trajectories and score matching or variational learning, thus reducing the memory load and difficulty in end-to-end training. We also develop adaptive time reparameterization of the flow network with a progressive refinement of the induced trajectory in probability space to improve the model accuracy further. Experiments with synthetic and real data show that the proposed JKO-iFlow network achieves competitive performance compared with existing flow and diffusion models at a significantly reduced computational and memory cost.
SlotDiffusion: Object-Centric Generative Modeling with Diffusion Models
Ziyi Wu, Jingyu Hu, Wuyue Lu, Igor Gilitschenski, Animesh Garg
Object-centric learning aims to represent visual data with a set of object entities (a.k.a. slots), providing structured representations that enable systematic generalization.Leveraging advanced architectures like Transformers, recent approaches have made significant progress in unsupervised object discovery.In addition, slot-based representations hold great potential for generative modeling, such as controllable image generation and object manipulation in image editing.However, current slot-based methods often produce blurry images and distorted objects, exhibiting poor generative modeling capabilities.In this paper, we focus on improving slot-to-image decoding, a crucial aspect for high-quality visual generation.We introduce SlotDiffusion — an object-centric Latent Diffusion Model (LDM) designed for both image and video data.Thanks to the powerful modeling capacity of LDMs, SlotDiffusion surpasses previous slot models in unsupervised object segmentation and visual generation across six datasets.Furthermore, our learned object features can be utilized by existing object-centric dynamics models, improving video prediction quality and downstream temporal reasoning tasks.Finally, we demonstrate the scalability of SlotDiffusion to unconstrained real-world datasets such as PASCAL VOC and COCO, when integrated with self-supervised pre-trained image encoders.
StyleDrop: Text-to-Image Synthesis of Any Style
Kihyuk Sohn, Lu Jiang, Jarred Barber, Kimin Lee, Nataniel Ruiz, Dilip Krishnan, Huiwen Chang, Yuanzhen Li, Irfan Essa, Michael Rubinstein, Yuan Hao, Glenn Entis, Irina Blok, Daniel Castro Chin
Pre-trained large text-to-image models synthesize impressive images with an appropriate use of text prompts. However, ambiguities inherent in natural language, and out-of-distribution effects make it hard to synthesize arbitrary image styles, leveraging a specific design pattern, texture or material. In this paper, we introduce *StyleDrop*, a method that enables the synthesis of images that faithfully follow a specific style using a text-to-image model. StyleDrop is extremely versatile and captures nuances and details of a user-provided style, such as color schemes, shading, design patterns, and local and global effects. StyleDrop works by efficiently learning a new style by fine-tuning very few trainable parameters (less than 1\% of total model parameters), and improving the quality via iterative training with either human or automated feedback. Better yet, StyleDrop is able to deliver impressive results even when the user supplies only a *single* image specifying the desired style. An extensive study shows that, for the task of style tuning text-to-image models, StyleDrop on Muse convincingly outperforms other methods, including DreamBooth and textual inversion on Imagen or Stable Diffusion. More results are available at our project website: [https://styledrop.github.io](https://styledrop.github.io).
Training Energy-Based Normalizing Flow with Score-Matching Objectives
Chen-Hao Chao, Wei-Fang Sun, Yen-Chang Hsu, Zsolt Kira, Chun-Yi Lee
In this paper, we establish a connection between the parameterization of flow-based and energy-based generative models, and present a new flow-based modeling approach called energy-based normalizing flow (EBFlow). We demonstrate that by optimizing EBFlow with score-matching objectives, the computation of Jacobian determinants for linear transformations can be entirely bypassed. This feature enables the use of arbitrary linear layers in the construction of flow-based models without increasing the computational time complexity of each training iteration from $\mathcal{O}(D^2L)$ to $\mathcal{O}(D^3L)$ for an $L$-layered model that accepts $D$-dimensional inputs. This makes the training of EBFlow more efficient than the commonly-adopted maximum likelihood training method. In addition to the reduction in runtime, we enhance the training stability and empirical performance of EBFlow through a number of techniques developed based on our analysis of the score-matching methods. The experimental results demonstrate that our approach achieves a significant speedup compared to maximum likelihood estimation while outperforming prior methods with a noticeable margin in terms of negative log-likelihood (NLL).
Genetics, Cell Biology, etc
Deep Momentum Multi-Marginal Schrödinger Bridge
Tianrong Chen, Guan-Horng Liu, Molei Tao, Evangelos Theodorou
It is a crucial challenge to reconstruct population dynamics using unlabeled samples from distributions at coarse time intervals. Recent approaches such as flow-based models or Schrödinger Bridge (SB) models have demonstrated appealing performance, yet the inferred sample trajectories either fail to account for the underlying stochasticity or are unnecessarily rigid. In this article, we extend SB into phase space and propose $\underline{D}$eep $\underline{M}$omentum Multi-Marginal $\underline{S}$chrödinger $\underline{B}$ridge (DMSB), a novel computational framework that learns the smooth measure-valued spline for stochastic systems that satisfy position marginal constraints across time. By tailoring the celebrated Bregman Iteration and extending the Iteration Proportional Fitting to phase space, we manage to handle high-dimensional multi-marginal trajectory inference tasks efficiently. Our algorithm outperforms baselines significantly, as evidenced by experiments for synthetic datasets and a real-world single-cell RNA sequence dataset. Additionally, the proposed approach can reasonably reconstruct the evolution of velocity distribution, from position snapshots only, when there is a ground truth velocity that is nevertheless inaccessible.
xTrimoGene: An Efficient and Scalable Representation Learner for Single-Cell RNA-Seq Data
Jing Gong, Minsheng Hao, Xingyi Cheng, Xin Zeng, Chiming Liu, Jianzhu Ma, Xuegong Zhang, Taifeng Wang, Le Song
Advances in high-throughput sequencing technology have led to significant progress in measuring gene expressions at the single-cell level. The amount of publicly available single-cell RNA-seq (scRNA-seq) data is already surpassing 50M records for humans with each record measuring 20,000 genes. This highlights the need for unsupervised representation learning to fully ingest these data, yet classical transformer architectures are prohibitive to train on such data in terms of both computation and memory. To address this challenge, we propose a novel asymmetric encoder-decoder transformer for scRNA-seq data, called xTrimoGene$^\alpha$ (or xTrimoGene for short), which leverages the sparse characteristic of the data to scale up the pre-training. This scalable design of xTrimoGene reduces FLOPs by one to two orders of magnitude compared to classical transformers while maintaining high accuracy, enabling us to train the largest transformer models over the largest scRNA-seq dataset today. Our experiments also show that the performance of xTrimoGene improves as we scale up the model sizes, and it also leads to SOTA performance over various downstream tasks, such as cell type annotation, perturb-seq effect prediction, and drug combination prediction. xTrimoGene model is now available for use as a service via the following link: https://api.biomap.com/xTrimoGene/apply.
Graph Neural Networks
Is Distance Matrix Enough for Geometric Deep Learning?
Zian Li, Xiyuan Wang, Yinan Huang, Muhan Zhang
Graph Neural Networks (GNNs) are often used for tasks involving the 3D geometry of a given graph, such as molecular dynamics simulation. While incorporating Euclidean distance into Message Passing Neural Networks (referred to as Vanilla DisGNN) is a straightforward way to learn the geometry, it has been demonstrated that Vanilla DisGNN is geometrically incomplete. In this work, we first construct families of novel and symmetric geometric graphs that Vanilla DisGNN cannot distinguish even when considering all-pair distances, which greatly expands the existing counterexample families. Our counterexamples show the inherent limitation of Vanilla DisGNN to capture symmetric geometric structures. We then propose $k$-DisGNNs, which can effectively exploit the rich geometry contained in the distance matrix. We demonstrate the high expressive power of $k$-DisGNNs from three perspectives: 1. They can learn high-order geometric information that cannot be captured by Vanilla DisGNN. 2. They can unify some existing well-designed geometric models. 3. They are universal function approximators from geometric graphs to scalars (when $k\geq 2$) and vectors (when $k\geq 3$). Most importantly, we establish a connection between geometric deep learning (GDL) and traditional graph representation learning (GRL), showing that those highly expressive GNN models originally designed for GRL can also be applied to GDL with impressive performance, and that existing complicated, equivariant models are not the only solution. Experiments verify our theory. Our $k$-DisGNNs achieve many new state-of-the-art results on MD17.
Layer-Neighbor Sampling — Defusing Neighborhood Explosion in GNNs
Muhammed Fatih Balin, Ümit Çatalyürek
Graph Neural Networks (GNNs) have received significant attention recently, but training them at a large scale remains a challenge.Mini-batch training coupled with sampling is used to alleviate this challenge.However, existing approaches either suffer from the neighborhood explosion phenomenon or have suboptimal performance. To address these issues, we propose a new sampling algorithm called LAyer-neighBOR sampling (LABOR). It is designed to be a direct replacement for Neighbor Sampling (NS) with the same fanout hyperparameter while sampling up to 7 times fewer vertices, without sacrificing quality.By design, the variance of the estimator of each vertex matches NS from the point of view of a single vertex.Moreover, under the same vertex sampling budget constraints, LABOR converges faster than existing layer sampling approaches and can use up to 112 times larger batch sizes compared to NS.
Language, Speech and Dialog
Alexa Arena: A User-Centric Interactive Platform for Embodied AI
Qiaozi Gao, Govindarajan Thattai, Suhaila Shakiah, Xiaofeng Gao, Shreyas Pansare, Vasu Sharma, Gaurav Sukhatme, Hangjie Shi, Bofei Yang, Desheng Zhang, Lucy Hu, Karthika Arumugam, Shui Hu, Matthew Wen, Dinakar Guthy, Shunan Chung, Rohan Khanna, Osman Ipek, Leslie Ball, Kate Bland, Heather Rocker, Michael Johnston, Reza Ghanadan, Dilek Hakkani-Tur, Prem Natarajan
We introduce Alexa Arena, a user-centric simulation platform to facilitate research in building assistive conversational embodied agents. Alexa Arena features multi-room layouts and an abundance of interactable objects. With user-friendly graphics and control mechanisms, the platform supports the development of gamified robotic tasks readily accessible to general human users, allowing high-efficiency data collection and EAI system evaluation. Along with the platform, we introduce a dialog-enabled task completion benchmark with online human evaluations.
HyPoradise: An Open Baseline for Generative Speech Recognition with Large Language Models
Chen Chen, Yuchen Hu, Chao-Han Huck Yang, Sabato Marco Siniscalchi, Pin-Yu Chen, Ensiong Chng
Advancements in deep neural networks have allowed automatic speech recognition (ASR) systems to attain human parity on several publicly available clean speech datasets. However, even state-of-the-art ASR systems experience performance degradation when confronted with adverse conditions, as a well-trained acoustic model is sensitive to variations in the speech domain, e.g., background noise. Intuitively, humans address this issue by relying on their linguistic knowledge: the meaning of ambiguous spoken terms is usually inferred from contextual cues thereby reducing the dependency on the auditory system. Inspired by this observation, we introduce the first open-source benchmark to utilize external large language models (LLMs) for ASR error correction, where N-best decoding hypotheses provide informative elements for true transcription prediction. This approach is a paradigm shift from the traditional language model rescoring strategy that can only select one candidate hypothesis as output transcription. The proposed benchmark contains a novel dataset, “HyPoradise” (HP), encompassing more than 316,000 pairs of N-best hypotheses and corresponding accurate transcriptions across prevalent speech domains. Given this dataset, we examine three types of error correction techniques based on LLMs with varying amounts of labeled hypotheses-transcription pairs, which gains significant word error rate (WER) reduction. Experimental evidence demonstrates the proposed technique achieves a breakthrough by surpassing the upper bound of traditional re-ranking based methods. More surprisingly, LLM with reasonable prompt design can even correct those tokens that are missing in N-best list. We make our results publicly accessible for reproducible pipelines with released pre-trained models, thus providing a new paradigm for ASR error correction with LLMs.
Open Visual Knowledge Extraction via Relation-Oriented Multimodality Model Prompting
Hejie Cui, Xinyu Fang, Zihan Zhang, Ran Xu, Xuan Kan, Xin Liu, Yue Yu, Manling Li, Yangqiu Song, Carl Yang
Images contain rich relational knowledge that can help machines understand the world. Existing methods on visual knowledge extraction often rely on the pre-defined format (e.g., sub-verb-obj tuples) or vocabulary (e.g., relation types), restricting the expressiveness of the extracted knowledge. In this work, we take a first exploration to a new paradigm of open visual knowledge extraction. To achieve this, we present OpenVik which consists of an open relational region detector to detect regions potentially containing relational knowledge and a visual knowledge generator that generates format-free knowledge by prompting the large multimodality model with the detected region of interest. We also explore two data enhancement techniques for diversifying the generated format-free visual knowledge. Extensive knowledge quality evaluations highlight the correctness and uniqueness of the extracted open visual knowledge by OpenVik. Moreover, integrating our extracted knowledge across various visual reasoning applications shows consistent improvements, indicating the real-world applicability of OpenVik.
OpenAssistant Conversations – Democratizing Large Language Model Alignment
Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi Rui Tam, Keith Stevens, Abdullah Barhoum, Duc Nguyen, Oliver Stanley, Richárd Nagyfi, Shahul ES, Sameer Suri, David Glushkov, Arnav Dantuluri, Andrew Maguire, Christoph Schuhmann, Huu Nguyen, Alexander Mattick
Aligning large language models (LLMs) with human preferences has proven to drastically improve usability and has driven rapid adoption as demonstrated by ChatGPT.Alignment techniques such as supervised fine-tuning (\textit{SFT}) and reinforcement learning from human feedback (\textit{RLHF}) greatly reduce the required skill and domain knowledge to effectively harness the capabilities of LLMs, increasing their accessibility and utility across various domains.However, state-of-the-art alignment techniques like \textit{RLHF} rely on high-quality human feedback data, which is expensive to create and often remains proprietary.In an effort to democratize research on large-scale alignment, we release OpenAssistant Conversations, a human-generated, human-annotated assistant-style conversation corpus consisting of 161,443 messages in 35 different languages, annotated with 461,292 quality ratings, resulting in over 10,000 complete and fully annotated conversation trees.The corpus is a product of a worldwide crowd-sourcing effort involving over 13,500 volunteers.Models trained on OpenAssistant Conversations show consistent improvements on standard benchmarks over respective base models.We release our code\footnote{\git} and data\footnote{\data} under a fully permissive licence.
PopSign ASL v1.0: An Isolated American Sign Language Dataset Collected via Smartphones
Thad Starner, Sean Forbes, Matthew So, David Martin, Rohit Sridhar, Gururaj Deshpande, Sam Sepah, Sahir Shahryar, Khushi Bhardwaj, Tyler Kwok, Daksh Sehgal, Saad Hassan, Bill Neubauer, Sofia Vempala, Alec Tan, Jocelyn Heath, Unnathi Kumar, Priyanka Mosur, Tavenner Hall, Rajandeep Singh, Christopher Cui, Glenn Cameron, Sohier Dane, Garrett Tanzer
PopSign is a smartphone-based bubble-shooter game that helps hearing parentsof deaf infants learn sign language. To help parents practice their ability to sign,PopSign is integrating sign language recognition as part of its gameplay. Fortraining the recognizer, we introduce the PopSign ASL v1.0 dataset that collectsexamples of 250 isolated American Sign Language (ASL) signs using Pixel 4Asmartphone selfie cameras in a variety of environments. It is the largest publiclyavailable, isolated sign dataset by number of examples and is the first dataset tofocus on one-handed, smartphone signs. We collected over 210,000 examplesat 1944×2592 resolution made by 47 consenting Deaf adult signers for whomAmerican Sign Language is their primary language. We manually reviewed 217,866of these examples, of which 175,023 (approximately 700 per sign) were the signintended for the educational game. 39,304 examples were recognizable as a signbut were not the desired variant or were a different sign. We provide a training setof 31 signers, a validation set of eight signers, and a test set of eight signers. Abaseline LSTM model for the 250-sign vocabulary achieves 82.1% accuracy (81.9%class-weighted F1 score) on the validation set and 84.2% (83.9% class-weightedF1 score) on the test set. Gameplay suggests that accuracy will be sufficient forcreating educational games involving sign language recognition.
ToolQA: A Dataset for LLM Question Answering with External Tools
Yuchen Zhuang, Yue Yu, Kuan Wang, Haotian Sun, Chao Zhang
Large Language Models (LLMs) have demonstrated impressive performance in various NLP tasks, but they still suffer from challenges such as hallucination and weak numerical reasoning. To overcome these challenges, external tools can be used to enhance LLMs’ question-answering abilities. However, current evaluation methods do not distinguish between questions that can be answered using LLMs’ internal knowledge and those that require external information through tool use. To address this issue, we introduce a new dataset called ToolQA, which is designed to faithfully evaluate LLMs’ ability to use external tools for question answering. Our development of ToolQA involved a scalable, automated process for dataset curation, along with 13 specialized tools designed for interaction with external knowledge in order to answer questions. Importantly, we strive to minimize the overlap between our benchmark data and LLMs’ pre-training data, enabling a more precise evaluation of LLMs’ tool-use reasoning abilities. We conducted an in-depth diagnosis of existing tool-use LLMs to highlight their strengths, weaknesses, and potential improvements. Our findings set a new benchmark for evaluating LLMs and suggest new directions for future advancements. Our data and code are freely available for the broader scientific community on GitHub.
Large Scale, Parallel and Distributed
FLuID: Mitigating Stragglers in Federated Learning using Invariant Dropout
Irene Wang, Prashant Nair, Divya Mahajan
Federated Learning (FL) allows machine learning models to train locally on individual mobile devices, synchronizing model updates via a shared server. This approach safeguards user privacy; however, it also generates a heterogeneous training environment due to the varying performance capabilities across devices. As a result, “straggler” devices with lower performance often dictate the overalltraining time in FL. In this work, we aim to alleviate this performance bottleneck due to stragglers by dynamically balancing the training load across the system. We introduce Invariant Dropout, a method that extracts a sub-model based on the weight update threshold, thereby minimizing potential impacts on accuracy. Building on this dropout technique, we develop an adaptive training framework, Federated Learning using Invariant Dropout (FLuID). FLuID offers a lightweight sub-model extraction to regulate computational intensity, thereby reducing the load on straggler devices without affecting model quality. Our method leverages neuron updates from non-straggler devices to construct a tailored sub-model for each straggler based on client performance profiling. Furthermore, FLuID can dynamically adapt to changes in stragglers as runtime conditions shift. We evaluate FLuID using five real-world mobile clients. The evaluations show that Invariant Dropout maintains baseline model efficiency while alleviating the performance bottleneck of stragglers through a dynamic, runtime approach.
Learning Theory
Contrastive Moments: Unsupervised Halfspace Learning in Polynomial Time
Xinyuan Cao, Santosh Vempala
We give a polynomial-time algorithm for learning high-dimensional halfspaces with margins in $d$-dimensional space to within desired TV distance when the ambient distribution is an unknown affine transformation of the $d$-fold product of an (unknown) symmetric one-dimensional logconcave distribution, and the halfspace is introduced by deleting at least an $\epsilon$ fraction of the data in one of the component distributions. Notably, our algorithm does not need labels and establishes the unique (and efficient) identifiability of the hidden halfspace under this distributional assumption. The sample and time complexity of the algorithm are polynomial in the dimension and $1/\epsilon$. The algorithm uses only the first two moments of *suitable re-weightings* of the empirical distribution, which we call *contrastive moments*; its analysis uses classical facts about generalized Dirichlet polynomials and relies crucially on a new monotonicity property of the moment ratio of truncations of logconcave distributions. Such algorithms, based only on first and second moments were suggested in earlier work, but hitherto eluded rigorous guarantees.Prior work addressed the special case when the underlying distribution is Gaussian via Non-Gaussian Component Analysis. We improve on this by providing polytime guarantees based on Total Variation (TV) distance, in place of existing moment-bound guarantees that can be super-polynomial. Our work is also the first to go beyond Gaussians in this setting.
Perceptual adjustment queries and an inverted measurement paradigm for low-rank metric learning
Austin Xu, Andrew McRae, Jingyan Wang, Mark Davenport, Ashwin Pananjady
We introduce a new type of query mechanism for collecting human feedback, called the perceptual adjustment query (PAQ). Being both informative and cognitively lightweight, the PAQ adopts an inverted measurement scheme, and combines advantages from both cardinal and ordinal queries. We showcase the PAQ in the metric learning problem, where we collect PAQ measurements to learn an unknown Mahalanobis distance. This gives rise to a high-dimensional, low-rank matrix estimation problem to which standard matrix estimators cannot be applied. Consequently, we develop a two-stage estimator for metric learning from PAQs, and provide sample complexity guarantees for this estimator. We present numerical simulations demonstrating the performance of the estimator and its notable properties.
Multi-agent
Mixed-Initiative Multiagent Apprenticeship Learning for Human Training of Robot Teams
Esmaeil Seraj, Jerry Xiong, Mariah Schrum, Matthew Gombolay
Extending recent advances in Learning from Demonstration (LfD) frameworks to multi-robot settings poses critical challenges such as environment non-stationarity due to partial observability which is detrimental to the applicability of existing methods. Although prior work has shown that enabling communication among agents of a robot team can alleviate such issues, creating inter-agent communication under existing Multi-Agent LfD (MA-LfD) frameworks requires the human expert to provide demonstrations for both environment actions and communication actions, which necessitates an efficient communication strategy on a known message spaces. To address this problem, we propose Mixed-Initiative Multi-Agent Apprenticeship Learning (MixTURE). MixTURE enables robot teams to learn from a human expert-generated data a preferred policy to accomplish a collaborative task, while simultaneously learning emergent inter-agent communication to enhance team coordination. The key ingredient to MixTURE’s success is automatically learning a communication policy, enhanced by a mutual-information maximizing reverse model that rationalizes the underlying expert demonstrations without the need for human generated data or an auxiliary reward function. MixTURE outperforms a variety of relevant baselines on diverse data generated by human experts in complex heterogeneous domains. MixTURE is the first MA-LfD framework to enable learning multi-robot collaborative policies directly from real human data, resulting in ~44% less human workload, and ~46% higher usability score.
Alexander Bukharin, Yan Li, Yue Yu, Qingru Zhang, Zhehui Chen, Simiao Zuo, Chao Zhang, Songan Zhang, Tuo Zhao
Multi-Agent Reinforcement Learning (MARL) has shown promising results across several domains. Despite this promise, MARL policies often lack robustness and are therefore sensitive to small changes in their environment. This presents a serious concern for the real world deployment of MARL algorithms, where the testing environment may slightly differ from the training environment. In this work we show that we can gain robustness by controlling a policy’s Lipschitz constant, and under mild conditions, establish the existence of a Lipschitz and close-to-optimal policy. Motivated by these insights, we propose a new robust MARL framework, ERNIE, that promotes the Lipschitz continuity of the policies with respect to the state observations and actions by adversarial regularization. The ERNIE framework provides robustness against noisy observations, changing transition dynamics, and malicious actions of agents. However, ERNIE’s adversarial regularization may introduce some training instability. To reduce this instability, we reformulate adversarial regularization as a Stackelberg game. We demonstrate the effectiveness of the proposed framework with extensive experiments in traffic light control and particle environments. In addition, we extend ERNIE to mean-field MARL with a formulation based on distributionally robust optimization that outperforms its non-robust counterpart and is of independent interest. Our code is available at https://github.com/abukharin3/ERNIE.
Neuroscience, Cognitive Science
A Unified, Scalable Framework for Neural Population Decoding
Mehdi Azabou, Vinam Arora, Venkataramana Ganesh, Ximeng Mao, Santosh Nachimuthu, Michael Mendelson, Blake Richards, Matthew Perich, Guillaume Lajoie, Eva Dyer
Our ability to use deep learning approaches to decipher neural activity would likely benefit from greater scale, in terms of both the model size and the datasets. However, the integration of many neural recordings into one unified model is challenging, as each recording contains the activity of different neurons from different individual animals. In this paper, we introduce a training framework and architecture designed to model the population dynamics of neural activity across diverse, large-scale neural recordings. Our method first tokenizes individual spikes within the dataset to build an efficient representation of neural events that captures the fine temporal structure of neural activity. We then employ cross-attention and a PerceiverIO backbone to further construct a latent tokenization of neural population activities. Utilizing this architecture and training framework, we construct a large-scale multi-session model trained on large datasets from seven nonhuman primates, spanning over 158 different sessions of recording from over 27,373 neural units and over 100 hours of recordings. In a number of different tasks, we demonstrate that our pretrained model can be rapidly adapted to new, unseen sessions with unspecified neuron correspondence, enabling few-shot performance with minimal labels. This work presents a powerful new approach for building deep learning tools to analyze neural data and stakes out a clear path to training at scale for neural decoding models.
Yule Wang, Zijing Wu, Chengrui Li, Anqi Wu
In the field of behavior-related brain computation, it is necessary to align raw neural signals against the drastic domain shift among them. A foundational framework within neuroscience research posits that trial-based neural population activities rely on low-dimensional latent dynamics, thus focusing on the latter greatly facilitates the alignment procedure. Despite this field’s progress, existing methods ignore the intrinsic spatio-temporal structure during the alignment phase. Hence, their solutions usually lead to poor quality in latent dynamics structures and overall performance. To tackle this problem, we propose an alignment method ERDiff, which leverages the expressivity of the diffusion model to preserve the spatio-temporal structure of latent dynamics. Specifically, the latent dynamics structures of the source domain are first extracted by a diffusion model. Then, under the guidance of this diffusion model, such structures are well-recovered through a maximum likelihood alignment procedure in the target domain. We first demonstrate the effectiveness of our proposed method on a synthetic dataset. Then, when applied to neural recordings from the non-human primate motor cortex, under both cross-day and inter-subject settings, our method consistently manifests its capability of preserving the spatio-temporal structure of latent dynamics and outperforms existing approaches in alignment goodness-of-fit and neural decoding performance.
Online Learning and Bandits
Faster Margin Maximization Rates for Generic Optimization Methods
Guanghui Wang, Zihao Hu, Vidya Muthukumar, Jacob Abernethy
First-order optimization methods tend to inherently favor certain solutions over others when minimizing a given training objective with multiple local optima. This phenomenon, known as \emph{implicit bias}, plays a critical role in understanding the generalization capabilities of optimization algorithms. Recent research has revealed that gradient-descent-based methods exhibit an implicit bias for the $\ell_2$-maximal margin classifier in the context of separable binary classification. In contrast, generic optimization methods, such as mirror descent and steepest descent, have been shown to converge to maximal margin classifiers defined by alternative geometries. However, while gradient-descent-based algorithms demonstrate fast implicit bias rates, the implicit bias rates of generic optimization methods have been relatively slow. To address this limitation, in this paper, we present a series of state-of-the-art implicit bias rates for mirror descent and steepest descent algorithms. Our primary technique involves transforming a generic optimization algorithm into an online learning dynamic that solves a regularized bilinear game, providing a unified framework for analyzing the implicit bias of various optimization methods. The accelerated rates are derived leveraging the regret bounds of online learning algorithms within this game framework.
Riemannian Projection-free Online Learning
Zihao Hu, Guanghui Wang, Jacob Abernethy
The projection operation is a critical component in a wide range of optimization algorithms, such as online gradient descent (OGD), for enforcing constraints and achieving optimal regret bounds. However, it suffers from computational complexity limitations in high-dimensional settings or when dealing with ill-conditioned constraint sets. Projection-free algorithms address this issue by replacing the projection oracle with more efficient optimization subroutines. But to date, these methods have been developed primarily in the Euclidean setting, and while there has been growing interest in optimization on Riemannian manifolds, there has been essentially no work in trying to utilize projection-free tools here. An apparent issue is that non-trivial affine functions are generally non-convex in such domains. In this paper, we present methods for obtaining sub-linear regret guarantees in online geodesically convex optimization on curved spaces for two scenarios: when we have access to (a) a separation oracle or (b) a linear optimization oracle. For geodesically convex losses, and when a separation oracle is available, our algorithms achieve $O(T^{\frac{1}{2}})$, $O(T^{\frac{3}{4}})$ and $O(T^{\frac{1}{2}})$ adaptive regret guarantees in the full information setting, the bandit setting with one-point feedback and the bandit setting with two-point feedback, respectively. When a linear optimization oracle is available, we obtain regret rates of $O(T^{\frac{3}{4}})$ for geodesically convex losses and $O(T^{\frac{2}{3}}\log T)$ for strongly geodesically convex losses.
Physics
PETAL: Physics Emulation Through Averaged Linearizations for Solving Inverse Problems
Jihui Jin, Etienne Ollivier, Richard Touret, Matthew McKinley, Karim Sabra, Justin Romberg
Inverse problems describe the task of recovering an underlying signal of interest given observables. Typically, the observables are related via some non-linear forward model applied to the underlying unknown signal. Inverting the non-linear forward model can be computationally expensive, as it often involves computing and inverting a linearization at a series of estimates. Rather than inverting the physics-based model, we instead train a surrogate forward model (emulator) and leverage modern auto-grad libraries to solve for the input within a classical optimization framework. Current methods to train emulators are done in a black box supervised machine learning fashion and fail to take advantage of any existing knowledge of the forward model. In this article, we propose a simple learned weighted average model that embeds linearizations of the forward model around various reference points into the model itself, explicitly incorporating known physics. Grounding the learned model with physics based linearizations improves the forward modeling accuracy and provides richer physics based gradient information during the inversion process leading to more accurate signal recovery. We demonstrate the efficacy on an ocean acoustic tomography (OAT) example that aims to recover ocean sound speed profile (SSP) variations from acoustic observations (e.g. eigenray arrival times) within simulation of ocean dynamics in the Gulf of Mexico.
Planning
AdaPlanner: Adaptive Planning from Feedback with Language Models
Haotian Sun, Yuchen Zhuang, Lingkai Kong, Bo Dai, Chao Zhang
Large language models (LLMs) have recently demonstrated the potential in acting as autonomous agents for sequential decision-making tasks. However, most existing methods either take actions greedily without planning or rely on static plans that are not adaptable to environmental feedback. Consequently, the sequential decision-making performance of LLM agents degenerates with problem complexity and plan horizons increase. We propose a closed-loop approach, AdaPlanner, which allows the LLM agent to refine its self-generated plan adaptively in response to environmental feedback. In AdaPlanner, the LLM agent adaptively refines its plan from feedback with both in-plan and out-of-plan refinement strategies. To mitigate hallucination, we develop a code-style LLM prompt structure that facilitates plan generation across a variety of tasks, environments, and agent capabilities. Furthermore, we propose a skill discovery mechanism that leverages successful plans as few-shot exemplars, enabling the agent to plan and refine with fewer task demonstrations. Our experiments in the ALFWorld and MiniWoB++ environments demonstrate that AdaPlanner outperforms state-of-the-art baselines by 3.73% and 4.11% while utilizing 2x and 600x fewer samples, respectively. The implementation of AdaPlanner is available at https://github.com/haotiansun14/AdaPlanner.
GraphMP: Graph Neural Network-based Motion Planning with Efficient Graph Search
Xiao Zang, Miao Yin, Jinqi Xiao, Saman Zonouz, Bo Yuan
Motion planning, which aims to find a high-quality collision-free path in the configuration space, is a fundamental task in robotic systems. Recently, learning-based motion planners, especially the graph neural network-powered, have shown promising planning performance. However, though the state-of-the-art GNN planner can efficiently extract and learn graph information, its inherent mechanism is not well suited for graph search process, hindering its further performance improvement. To address this challenge and fully unleash the potential of GNN in motion planning, this paper proposes GraphMP, a neural motion planner for both low and high-dimensional planning tasks. With the customized model architecture and training mechanism design, GraphMP can simultaneously perform efficient graph pattern extraction and graph search processing, leading to strong planning performance. Experiments on a variety of environments, ranging from 2D Maze to 14D dual KUKA robotic arm, show that our proposed GraphMP achieves significant improvement on path quality and planning speed over the state-of-the-art learning-based and classical planners; while preserving the competitive success rate.
Privacy-preserving Statistics and Machine Learning
Bounding the Invertibility of Privacy-preserving Instance Encoding using Fisher Information
Kiwan Maeng, Chuan Guo, Sanjay Kariyappa, G. Edward Suh
Privacy-preserving instance encoding aims to encode raw data into feature vectors without revealing their privacy-sensitive information. When designed properly, these encodings can be used for downstream ML applications such as training and inference with limited privacy risk. However, the vast majority of existing schemes do not theoretically justify that their encoding is non-invertible, and their privacy-enhancing properties are only validated empirically against a limited set of attacks. In this paper, we propose a theoretically-principled measure for the invertibility of instance encoding based on Fisher information that is broadly applicable to a wide range of popular encoders. We show that dFIL can be used to bound the invertibility of encodings both theoretically and empirically, providing an intuitive interpretation of the privacy of instance encoding.
Reinforcement Learning and Planning
Bayesian Risk-Averse Q-Learning with Streaming Observations
Yuhao Wang, Enlu Zhou
We consider a robust reinforcement learning problem, where a learning agent learns from a simulated training environment. To account for the model mis-specification between this training environment and the true environment due to lack of data, we adopt a formulation of Bayesian risk MDP (BRMDP) with infinite horizon, which uses Bayesian posterior to estimate the transition model and impose a risk functional to account for the model uncertainty. Observations from the real environment that is out of the agent’s control arrive periodically and are utilized by the agent to update the Bayesian posterior to reduce model uncertainty. We theoretically demonstrate that BRMDP balances the trade-off between robustness and conservativeness, and we further develop a multi-stage Bayesian risk-averse Q-learning algorithm to solve BRMDP with streaming observations from real environment. The proposed algorithm learns a risk-averse yet optimal policy that depends on the availability of real-world observations. We provide a theoretical guarantee of strong convergence for the proposed algorithm.
Representation Learning
DAMEX: Dataset-aware Mixture-of-Experts for visual understanding of mixture-of-datasets
Yash Jain, Harkirat Behl, Zsolt Kira, Vibhav Vineet
Construction of a universal detector poses a crucial question: How can we most effectively train a model on a large mixture of datasets? The answer lies in learning dataset-specific features and ensembling their knowledge but do all this in a single model. Previous methods achieve this by having separate detection heads on a common backbone but that results in a significant increase in parameters. In this work, we present Mixture-of-Experts as a solution, highlighting that MoE are much more than a scalability tool. We propose Dataset-Aware Mixture-of-Experts, DAMEX where we train the experts to become an `expert’ of a dataset by learning to route each dataset tokens to its mapped expert. Experiments on Universal Object-Detection Benchmark show that we outperform the existing state-of-the-art by average +10.2 AP score and improve over our non-MoE baseline by average +2.0 AP score. We also observe consistent gains while mixing datasets with (1) limited availability, (2) disparate domains and (3) divergent label sets. Further, we qualitatively show that DAMEX is robust against expert representation collapse. Code is available at https://github.com/jinga-lala/DAMEX
Robotics
3D-IntPhys: Towards More Generalized 3D-grounded Visual Intuitive Physics under Challenging Scenes
Haotian Xue, Antonio Torralba, Josh Tenenbaum, Dan Yamins, Yunzhu Li, Hsiao-Yu Tung
Given a visual scene, humans have strong intuitions about how a scene can evolve over time under given actions. The intuition, often termed visual intuitive physics, is a critical ability that allows us to make effective plans to manipulate the scene to achieve desired outcomes without relying on extensive trial and error. In this paper, we present a framework capable of learning 3D-grounded visual intuitive physics models from videos of complex scenes with fluids. Our method is composed of a conditional Neural Radiance Field (NeRF)-style visual frontend and a 3D point-based dynamics prediction backend, using which we can impose strong relational and structural inductive bias to capture the structure of the underlying environment. Unlike existing intuitive point-based dynamics works that rely on the supervision of dense point trajectory from simulators, we relax the requirements and only assume access to multi-view RGB images and (imperfect) instance masks acquired using color prior. This enables the proposed model to handle scenarios where accurate point estimation and tracking are hard or impossible. We generate datasets including three challenging scenarios involving fluid, granular materials, and rigid objects in the simulation. The datasets do not include any dense particle information so most previous 3D-based intuitive physics pipelines can barely deal with that. We show our model can make long-horizon future predictions by learning from raw images and significantly outperforms models that do not employ an explicit 3D representation space. We also show that once trained, our model can achieve strong generalization in complex scenarios under extrapolate settings.
Where are we in the search for an Artificial Visual Cortex for Embodied Intelligence?
Arjun Majumdar, Karmesh Yadav, Sergio Arnaud, Jason Ma, Claire Chen, Sneha Silwal, Aryan Jain, Vincent-Pierre Berges, Tingfan Wu, Jay Vakil, Pieter Abbeel, Jitendra Malik, Dhruv Batra, Yixin Lin, Oleksandr Maksymets, Aravind Rajeswaran, Franziska Meier
We present the largest and most comprehensive empirical study of pre-trained visual representations (PVRs) or visual ‘foundation models’ for Embodied AI. First, we curate CortexBench, consisting of 17 different tasks spanning locomotion, navigation, dexterous, and mobile manipulation. Next, we systematically evaluate existing PVRs and find that none are universally dominant. To study the effect of pre-training data size and diversity, we combine over 4,000 hours of egocentric videos from 7 different sources (over 4.3M images) and ImageNet to train different-sized vision transformers using Masked Auto-Encoding (MAE) on slices of this data. Contrary to inferences from prior work, we find that scaling dataset size and diversity does not improve performance universally (but does so on average). Our largest model, named VC-1, outperforms all prior PVRs on average but does not universally dominate either. Next, we show that task- or domain-specific adaptation of VC-1 leads to substantial gains, with VC-1 (adapted) achieving competitive or superior performance than the best known results on all of the benchmarks in CortexBench. Finally, we present real-world hardware experiments, in which VC-1 and VC-1 (adapted) outperform the strongest pre-existing PVR. Overall, this paper presents no new techniques but a rigorous systematic evaluation, a broad set of findings about PVRs (that in some cases, refute those made in narrow domains in prior work), and open-sourced code and models (that required over 10,000 GPU-hours to train) for the benefit of the research community.
Robustness
Fast Trainable Projection for Robust Fine-tuning
Junjiao Tian, Yen-Cheng Liu, James S Smith, Zsolt Kira
Robust fine-tuning aims to achieve competitive in-distribution (ID) performance while maintaining the out-of-distribution (OOD) robustness of a pre-trained model when transferring it to a downstream task. Recently, projected gradient descent has been successfully used in robust fine-tuning by constraining the deviation from the initialization of the fine-tuned model explicitly through projection. However, algorithmically, two limitations prevent this method from being adopted more widely, scalability and efficiency. In this paper, we propose a new projection-based fine-tuning algorithm, Fast Trainable Projection (FTP) for computationally efficient learning of per-layer projection constraints, resulting in an average 35% speedup on our benchmarks compared to prior works. FTP can be combined with existing optimizers such as AdamW, and be used in a plug-and-play fashion. Finally, we show that FTP is a special instance of hyper-optimizers that tune the hyper-parameters of optimizers in a learnable manner through nested differentiation. Empirically, we show superior robustness on OOD datasets, including domain shifts and natural corruptions, across four different vision tasks with five different pre-trained models. Additionally, we demonstrate that FTP is broadly applicable and beneficial to other learning scenarios such as low-label and continual learning settings thanks to its easy adaptability. The code will be available at https://github.com/GT-RIPL/FTP.git.
Towards Last-Layer Retraining for Group Robustness with Fewer Annotations
Tyler LaBonte, Vidya Muthukumar, Abhishek Kumar
Empirical risk minimization (ERM) of neural networks is prone to over-reliance on spurious correlations and poor generalization on minority groups. The recent deep feature reweighting (DFR) technique achieves state-of-the-art group robustness via simple last-layer retraining, but it requires held-out group and class annotations to construct a group-balanced reweighting dataset. In this work, we examine this impractical requirement and find that last-layer retraining can be surprisingly effective with no group annotations (other than for model selection) and only a handful of class annotations. We first show that last-layer retraining can greatly improve worst-group accuracy even when the reweighting dataset has only a small proportion of worst-group data. This implies a “free lunch” where holding out a subset of training data to retrain the last layer can substantially outperform ERM on the entire dataset with no additional data, annotations, or computation for training. To further improve group robustness, we introduce a lightweight method called selective last-layer finetuning (SELF), which constructs the reweighting dataset using misclassifications or disagreements. Our experiments present the first evidence that model disagreement upsamples worst-group data, enabling SELF to nearly match DFR on four well-established benchmarks across vision and language tasks with no group annotations and less than 3% of the held-out class annotations.
Self-Supervised Learning
Mehdi Azabou, Michael Mendelson, Nauman Ahad, Maks Sorokin, Shantanu Thakoor, Carolina Urzay, Eva Dyer
Unconstrained and natural behavior consists of dynamics that are complex and unpredictable, especially when trying to predict what will happen multiple steps into the future. While some success has been found in building representations of animal behavior under constrained or simplified task-based conditions, many of these models cannot be applied to free and naturalistic settings where behavior becomes increasingly hard to model. In this work, we develop a multi-task representation learning model for animal behavior that combines two novel components: (i) an action-prediction objective that aims to predict the distribution of actions over future timesteps, and (ii) a multi-scale architecture that builds separate latent spaces to accommodate short- and long-term dynamics. After demonstrating the ability of the method to build representations of both local and global dynamics in robots in varying environments and terrains, we apply our method to the MABe 2022 Multi-Agent Behavior challenge, where our model ranks first overall on both mice and fly benchmarks. In all of these cases, we show that our model can build representations that capture the many different factors that drive behavior and solve a wide range of downstream tasks.
SSL4EO-L: Datasets and Foundation Models for Landsat Imagery
Adam Stewart, Nils Lehmann, Isaac Corley, Yi Wang, Yi-Chia Chang, Nassim Ait Ait Ali Braham, Shradha Sehgal, Caleb Robinson, Arindam Banerjee
The Landsat program is the longest-running Earth observation program in history, with 50+ years of data acquisition by 8 satellites. The multispectral imagery captured by sensors onboard these satellites is critical for a wide range of scientific fields. Despite the increasing popularity of deep learning and remote sensing, the majority of researchers still use decision trees and random forests for Landsat image analysis due to the prevalence of small labeled datasets and lack of foundation models. In this paper, we introduce SSL4EO-L, the first ever dataset designed for Self-Supervised Learning for Earth Observation for the Landsat family of satellites (including 3 sensors and 2 product levels) and the largest Landsat dataset in history (5M image patches). Additionally, we modernize and re-release the L7 Irish and L8 Biome cloud detection datasets, and introduce the first ML benchmark datasets for Landsats 4–5 TM and Landsat 7 ETM+ SR. Finally, we pre-train the first foundation models for Landsat imagery using SSL4EO-L and evaluate their performance on multiple semantic segmentation tasks. All datasets and model weights are available via the TorchGeo library, making reproducibility and experimentation easy, and enabling scientific advancements in the burgeoning field of remote sensing for a multitude of downstream applications.
Time Series
Wei Jin, Haitao Mao, Zheng Li, Haoming Jiang, Chen Luo, Hongzhi Wen, Haoyu Han, Hanqing Lu, Zhengyang Wang, Ruirui Li, Zhen Li, Monica Cheng, Rahul Goutam, Haiyang Zhang, Karthik Subbian, Suhang Wang, Yizhou Sun, Jiliang Tang, Bing Yin, Xianfeng Tang
Modeling customer shopping intentions is a crucial task for e-commerce, as it directly impacts user experience and engagement. Thus, accurately understanding customer preferences is essential for providing personalized recommendations. Session-based recommendation, which utilizes customer session data to predict their next interaction, has become increasingly popular. However, existing session datasets have limitations in terms of item attributes, user diversity, and dataset scale. As a result, they cannot comprehensively capture the spectrum of user behaviors and preferences.To bridge this gap, we present the Amazon Multilingual Multi-locale Shopping Session Dataset, namely Amazon-M2. It is the first multilingual dataset consisting of millions of user sessions from six different locales, where the major languages of products are English, German, Japanese, French, Italian, and Spanish.Remarkably, the dataset can help us enhance personalization and understanding of user preferences, which can benefit various existing tasks as well as enable new tasks. To test the potential of the dataset, we introduce three tasks in this work:(1) next-product recommendation, (2) next-product recommendation with domain shifts, and (3) next-product title generation.With the above tasks, we benchmark a range of algorithms on our proposed dataset, drawing new insights for further research and practice. In addition, based on the proposed dataset and tasks, we hosted a competition in the KDD CUP 2023 https://www.aicrowd.com/challenges/amazon-kdd-cup-23-multilingual-recommendation-challenge and have attracted thousands of users and submissions. The winning solutions and the associated workshop can be accessed at our website~https://kddcup23.github.io/.
Trustworthy Machine Learning
Differentially Private Decoupled Graph Convolutions for Multigranular Topology Protection
Eli Chien, Wei-Ning Chen, Chao Pan, Pan Li, Ayfer Ozgur, Olgica Milenkovic
Graph Neural Networks (GNNs) have proven to be highly effective in solving real-world learning problems that involve graph-structured data. However, GNNs can also inadvertently expose sensitive user information and interactions through their model predictions. To address these privacy concerns, Differential Privacy (DP) protocols are employed to control the trade-off between provable privacy protection and model utility. Applying standard DP approaches to GNNs directly is not advisable due to two main reasons. First, the prediction of node labels, which relies on neighboring node attributes through graph convolutions, can lead to privacy leakage. Second, in practical applications, the privacy requirements for node attributes and graph topology may differ. In the latter setting, existing DP-GNN models fail to provide multigranular trade-offs between graph topology privacy, node attribute privacy, and GNN utility. To address both limitations, we propose a new framework termed Graph Differential Privacy (GDP), specifically tailored to graph learning. GDP ensures both provably private model parameters as well as private predictions. Additionally, we describe a novel unified notion of graph dataset adjacency to analyze the properties of GDP for different levels of graph topology privacy. Our findings reveal that DP-GNNs, which rely on graph convolutions, not only fail to meet the requirements for multigranular graph topology privacy but also necessitate the injection of DP noise that scales at least linearly with the maximum node degree. In contrast, our proposed Differentially Private Decoupled Graph Convolutions (DPDGCs) represent a more flexible and efficient alternative to graph convolutions that still provides the necessary guarantees of GDP. To validate our approach, we conducted extensive experiments on seven node classification benchmarking and illustrative synthetic datasets. The results demonstrate that DPDGCs significantly outperform existing DP-GNNs in terms of privacy-utility trade-offs.
LANCE: Stress-testing Visual Models by Generating Language-guided Counterfactual Images
Viraj Prabhu, Sriram Yenamandra, Prithvijit Chattopadhyay, Judy Hoffman
We propose an automated algorithm to stress-test a trained visual model by generating language-guided counterfactual test images (LANCE). Our method leverages recent progress in large language modeling and text-based image editing to augment an IID test set with a suite of diverse, realistic, and challenging test images without altering model weights. We benchmark the performance of a diverse set of pre-trained models on our generated data and observe significant and consistent performance drops. We further analyze model sensitivity across different types of edits, and demonstrate its applicability at surfacing previously unknown class-level model biases in ImageNet. Code is available at https://github.com/virajprabhu/lance.
Lockdown: Backdoor Defense for Federated Learning with Isolated Subspace Training
Tiansheng Huang, Sihao Hu, Ka-Ho Chow, Fatih Ilhan, Selim Tekin, Ling Liu
Federated learning (FL) is vulnerable to backdoor attacks due to its distributed computing nature. Existing defense solution usually requires larger amount of computation in either the training or testing phase, which limits their practicality in the resource-constrain scenarios. A more practical defense, i.e., neural network (NN) pruning based defense has been proposed in centralized backdoor setting. However, our empirical study shows that traditional pruning-based solution suffers \textit{poison-coupling} effect in FL, which significantly degrades the defense performance.This paper presents Lockdown, an isolated subspace training method to mitigate the poison-coupling effect. Lockdown follows three key procedures. First, it modifies the training protocol by isolating the training subspaces for different clients. Second, it utilizes randomness in initializing isolated subspacess, and performs subspace pruning and subspace recovery to segregate the subspaces between malicious and benign clients. Third, it introduces quorum consensus to cure the global model by purging malicious/dummy parameters. Empirical results show that Lockdown achieves \textit{superior} and \textit{consistent} defense performance compared to existing representative approaches against backdoor attacks. Another value-added property of Lockdown is the communication-efficiency and model complexity reduction, which are both critical for resource-constrain FL scenario. Our code is available at \url{https://github.com/git-disl/Lockdown}.
Other
DataPerf: Benchmarks for Data-Centric AI Development
Mark Mazumder, Colby Banbury, Xiaozhe Yao, Bojan Karlaš, William Gaviria Rojas, Sudnya Diamos, Greg Diamos, Lynn He, Alicia Parrish, Hannah Rose Kirk, Jessica Quaye, Charvi Rastogi, Douwe Kiela, David Jurado, David Kanter, Rafael Mosquera, Will Cukierski, Juan Ciro, Lora Aroyo, Bilge Acun, Lingjiao Chen, Mehul Raje, Max Bartolo, Evan Sabri Eyuboglu, Amirata Ghorbani, Emmett Goodman, Addison Howard, Oana Inel, Tariq Kane, Christine R. Kirkpatrick, D. Sculley, Tzu-Sheng Kuo, Jonas Mueller, Tristan Thrush, Joaquin Vanschoren, Margaret Warren, Adina Williams, Serena Yeung, Newsha Ardalani, Praveen Paritosh, Ce Zhang, James Zou, Carole-Jean Wu, Cody Coleman, Andrew Ng, Peter Mattson, Vijay Janapa Reddi
Machine learning research has long focused on models rather than datasets, and prominent datasets are used for common ML tasks without regard to the breadth, difficulty, and faithfulness of the underlying problems. Neglecting the fundamental importance of data has given rise to inaccuracy, bias, and fragility in real-world applications, and research is hindered by saturation across existing dataset benchmarks. In response, we present DataPerf, a community-led benchmark suite for evaluating ML datasets and data-centric algorithms. We aim to foster innovation in data-centric AI through competition, comparability, and reproducibility. We enable the ML community to iterate on datasets, instead of just architectures, and we provide an open, online platform with multiple rounds of challenges to support this iterative development. The first iteration of DataPerf contains five benchmarks covering a wide spectrum of data-centric techniques, tasks, and modalities in vision, speech, acquisition, debugging, and diffusion prompting, and we support hosting new contributed benchmarks from the community. The benchmarks, online evaluation platform, and baseline implementations are open source, and the MLCommons Association will maintain DataPerf to ensure long-term benefits to academia and industry.
Enhancing User Intent Capture in Session-Based Recommendation with Attribute Patterns
Xin Liu, Zheng Li, Yifan Gao, Jingfeng Yang, Tianyu Cao, Zhengyang Wang, Bing Yin, Yangqiu Song
The goal of session-based recommendation in E-commerce is to predict the next item that an anonymous user will purchase based on the browsing and purchase history. However, constructing global or local transition graphs to supplement session data can lead to noisy correlations and user intent vanishing. In this work, we propose the Frequent Attribute Pattern Augmented Transformer (FAPAT) that characterizes user intents by building attribute transition graphs and matching attribute patterns. Specifically, the frequent and compact attribute patterns are served as memory to augment session representations, followed by a gate and a transformer block to fuse the whole session information. Through extensive experiments on two public benchmarks and 100 million industrial data in three domains, we demonstrate that FAPAT consistently outperforms state-of-the-art methods by an average of 4.5% across various evaluation metrics (Hits, NDCG, MRR). Besides evaluating the next-item prediction, we estimate the models’ capabilities to capture user intents via predicting items’ attributes and period-item recommendations.
Mehrdad Ghadiri, David Arbour, Tung Mai, Cameron Musco, Anup Rao
The design and analysis of randomized experiments is fundamental to many areas, from the physical and social sciences to industrial settings. Regression adjustment is a popular technique to reduce the variance of estimates obtained from experiments, by utilizing information contained in auxiliary covariates. While there is a large literature within the statistics community studying various approaches to regression adjustment and their asymptotic properties, little focus has been given to approaches in the finite population setting with non-asymptotic accuracy bounds. Further, prior work typically assumes that an entire population is exposed to an experiment, whereas practitioners often seek to minimize the number of subjects exposed to an experiment, for ethical and pragmatic reasons.In this work, we study the problems of estimating the sample mean, individual treatment effects, and average treatment effect with regression adjustment. We propose approaches that use techniques from randomized numerical linear algebra to sample a subset of the population on which to perform an experiment. We give non-asymptotic accuracy bounds for our methods and demonstrate that they compare favorably with prior approaches.
Learning Universal Policies via Text-Guided Video Generation
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schuurmans, Pieter Abbeel
A goal of artificial intelligence is to construct an agent that can solve a wide variety of tasks. Recent progress in text-guided image synthesis has yielded models with an impressive ability to generate complex novel images, exhibiting combinatorial generalization across domains. Motivated by this success, we investigate whether such tools can be used to construct more general-purpose agents. Specifically, we cast the sequential decision making problem as a text-conditioned video generation problem, where, given a text-encoded specification of a desired goal, a planner synthesizes a set of future frames depicting its planned actions in the future, after which control actions are extracted from the generated video. By leveraging text as the underlying goal specification, we are able to naturally and combinatorially generalize to novel goals. The proposed policy-as-video formulation can further represent environments with different state and action spaces in a unified space of images, which, for example, enables learning and generalization across a variety of robot manipulation tasks. Finally, by leveraging pretrained language embeddings and widely available videos from the internet, the approach enables knowledge transfer through predicting highly realistic video plans for real robots.
May the Force be with You: Unified Force-Centric Pre-Training for 3D Molecular Conformations
Rui Feng, Qi Zhu, Huan Tran, Binghong Chen, Aubrey Toland, Rampi Ramprasad, Chao Zhang
Recent works have shown the promise of learning pre-trained models for 3D molecular representation.However, existing pre-training models focus predominantly on equilibrium data and largely overlook off-equilibrium conformations.It is challenging to extend these methods to off-equilibrium data because their training objective relies on assumptions ofconformations being the local energy minima. We address this gap by proposing a force-centric pretraining model for 3D molecular conformations covering both equilibrium and off-equilibrium data.For off-equilibrium data, our model learns directly from their atomic forces. For equilibrium data, we introduce zero-force regularization and forced-based denoising techniques to approximate near-equilibrium forces.We obtain a unified pre-trained model for 3D molecular representation with over 15 million diverse conformations. Experiments show that, with our pre-training objective, we increase forces accuracy by around 3 times compared to the un-pre-trained Equivariant Transformer model. By incorporating regularizations on equilibrium data, we solved the problem of unstable MD simulations in vanilla Equivariant Transformers, achieving state-of-the-art simulation performance with 2.45 times faster inference time than NequIP. As a powerful molecular encoder, our pre-trained model achieves on-par performance with state-of-the-art property prediction tasks.
Model-Based Reparameterization Policy Gradient Methods: Theory and Practical Algorithms
Shenao Zhang, Boyi Liu, Zhaoran Wang, Tuo Zhao
ReParameterization (RP) Policy Gradient Methods (PGMs) have been widely adopted for continuous control tasks in robotics and computer graphics. However, recent studies have revealed that, when applied to long-term reinforcement learning problems, model-based RP PGMs may experience chaotic and non-smooth optimization landscapes with exploding gradient variance, which leads to slow convergence. This is in contrast to the conventional belief that reparameterization methods have low gradient estimation variance in problems such as training deep generative models. To comprehend this phenomenon, we conduct a theoretical examination of model-based RP PGMs and search for solutions to the optimization difficulties. Specifically, we analyze the convergence of the model-based RP PGMs and pinpoint the smoothness of function approximators as a major factor that affects the quality of gradient estimation. Based on our analysis, we propose a spectral normalization method to mitigate the exploding variance issue caused by long model unrolls. Our experimental results demonstrate that proper normalization significantly reduces the gradient variance of model-based RP PGMs. As a result, the performance of the proposed method is comparable or superior to other gradient estimators, such as the Likelihood Ratio (LR) gradient estimator. Our code is available at https://github.com/agentification/RP_PGM.
Neural MMO 2.0: A Massively Multi-task Addition to Massively Multi-agent Learning
Joseph Suarez, David Bloomin, Kyoung Whan Choe, Hao Xiang Li, Ryan Sullivan, Nishaanth Kanna, Daniel Scott, Rose Shuman, Herbie Bradley, Louis Castricato, Phillip Isola, Chenghui Yu, Yuhao Jiang, Qimai Li, Jiaxin Chen, Xiaolong Zhu
Neural MMO 2.0 is a massively multi-agent and multi-task environment for reinforcement learning research. This version features a novel task-system that broadens the range of training settings and poses a new challenge in generalization: evaluation on and against tasks, maps, and opponents never seen during training. Maps are procedurally generated with 128 agents in the standard setting and 1-1024 supported overall. Version 2.0 is a complete rewrite of its predecessor with three-fold improved performance, effectively addressing simulation bottlenecks in online training. Enhancements to compatibility enable training with standard reinforcement learning frameworks designed for much simpler environments. Neural MMO 2.0 is free and open-source with comprehensive documentation available at neuralmmo.github.io and an active community Discord. To spark initial research on this new platform, we are concurrently running a competition at NeurIPS 2023.
See You in New Orleans!
*The research paper details from the main program that are listed above are made available from the conference organizers and/or through publicly available listings. Georgia Tech’s participation outside the main program (e.g. tutorials, workshops) is not listed due to limited resources and information. For all current conference program information visit https://neurips.cc/.
Development: College of Computing, Machine Learning Center
Web Lead; Data Graphics: Josh Preston
News: Nathan Deen
Data Source: NeurIPS 2023
Special Thanks: Terri Auricchio, Lee Campbell